
티스토리 뷰
한글판 johnsonj 2008.07.28 월
출처: http://coreapython.hosting.paran.com/howto/sebsauvage_net-%20Snyppets%20-%20Python%20snippets.htm#beginner
이 페이지에서는 수 많은 파이썬 조각코드와 요리법, 미니-가이드와 링크, 예제와 튜토리얼 그리고 아이디어를 아주 (아주) 기본에서부터 고급에 이르기까지 모두 다룬다.
모쪼록 도움이 되기를 바란다.
(잊지 마시고 본인의 메인 파이썬 페이지를 읽어 보시기 바란다 ( http://sebsauvage.net/python/ ): 다른 프로그램들도 보실 수 있고 윈도우즈 아래에서 C/C++로 자신만의 확장을 만드는 법을 보실 수 있다.)
- FTP를 사용하여 파일 전송하기
- 큐(FIFO) 그리고 스택(LIFO)
- 여러 값을 돌려주는 함수
- 두 변수의 내용을 교환하기
- 리스트에서 원소 중복 제거하기
- 웹 페이지에서 모든 링크 얻는 방법 (1)
- 웹 페이지에서 모든 링크 얻는 방법 (2)
- 웹 페이지에서 모든 링크 얻는 방법 (3)
- 웹 페이지에서 모든 링크 얻는 방법 (4)
- 파일 압축/풀기
- 디렉토리의 내용 나열하기
- 3줄 웹서버
- 따로 예외를 만들고 일으키기
- 파이썬으로 마이크로소프트 SQL 서버 스크립팅하기
- ODBC로 데이터베이스 접근하기
- ADO로 데이터베이스 접근하기
- 윈도우즈 아래에서 TinyWeb으로 CGI 처리법
- 파이썬 프로그램으로 .exe 파일 만들기
- 윈도우즈 레지스트리 읽기
- 파이썬 프로그램의 수행성능 측정하기
- 파이썬 프로그램 속도 높이기
- 정규 표현식은 과도한 경우가 있다
- 또다른 파이썬 프로그램 실행하기
- 베이시안 여과법
- Tkinter 그리고 cx_Freeze
- 몇가지 Tkinter 팁
- Tkinter 파일 대화상자
- 소스에 이진파일 포함시키는 법
- 좋은 관례: try/except 비-표준 반입 서술문
- 좋은 관례: 읽기가능한 객체
- 좋은 관례: 빈줄-점검 없이 read()
- 1.7이 1.7과 다르다고?
- 사용자의 홈 디렉토리 경로 얻기
- 파이썬의 가상 머신
- SQLite - 간단하게 만드는 데이터베이스
- 파이썬에 다이빙해 들어가기
- 윈도우즈 아래에서 상호배제(mutex) 만드는 법
- urllib2 그리고 프록시
- HTTP 요청에 적절한 사용자-중개자
- urllib2로 에러 처리하기
- urllib2: 뭘 받고 있는 거야?
- 방대한 XLS (Excel) 파일을 (읽고) 쓰기
- 스택 추적 저장하기
- 경고표시 여과하기
- PIL을 사용하여 JPEG 이미지를 저장하는 법
- 문자세트(Charsets)와 인코딩
- 반복하기(Iterating)
- 명령어-줄 해석(Parsing)하기
- 파이썬으로 AutoIt 사용하기
- 메인에는 무엇이 있는가
- html 페이지에서 모든 자바스크립트 비활성화시키기
- 곱셈
- .tar.bz2 압축파일 만들고 읽기
- 열거하기(Enumerating)
- Zip that thing
- 그리드를 채우는 Tkinter 위젯
- 문자열 날짜를 datetime 객체로 변환하기
- 초단위로 두 날짜 사이의 차 계산하기
- 속성 관리와 읽기-전용 속성
- 그 달의 첫 날 구하기
- 6줄로 RSS 2.0 감을 가져와서 읽어 해석하는 법
- BugMeNot으로 로그인 얻는 법
- 사이트에 접속해서 세션 쿠키 처리하는 법
- 구글 검색법
- 기본 GUI 어플리케이션 만들기
- 내포된 리스트와 터플 펴기
- 데이터베이스에서 거대 테이블 효과적으로 반복하기
- 부동소수점수의 범위
- RGB와 HSL 사이 변환법
- 무지개-색 파스텔 컬러의 팰리트 만드는 법
- 행렬 변환
- 파이썬에서 추상 클래스 만드는 법?
- matplotlib, PIL, 투명 PNG/GIF 그리고 ARGB와 RGBA 사이의 변환법
- 자동으로 이미지 자르는 법
- 단어 세기
- 신속한 코드 범위 검사
- wxPython 아래에서 콘솔로 예외 잡기
- Flickr로부터 무작위로 "흥미로운" 이미지 가져오기
- 왜 파이썬은 초보자의 언어로 좋은가?
- LDIF 파일 읽기
- 프로그램의 출력 잡기
- 웹 서버 만들기
- SOAP 클라이언트
- GMail 박스 보관하기
- HTTP POST 요청하기
- 줄 번호로 파일 읽기
- 문자열에서 허용된 문자만 남기고 여과하기
- 웹 서버 만들기(web.py 사용)
- 외부 링크
FTP를 사용하여 파일 전송하는 법
식은 죽 먹기다.
session = ftplib.FTP('myserver.com','login','passord') # FTP 서버에 접속
myfile = open('toto.txt','rb') # 전송할 파일 열기
session.storbinary('STOR toto.txt', myfile) # 파일 전송
myfile.close() # 파일 닫기
session.quit() # FTP 세션 닫기
큐(FIFO) 그리고 스택(LIFO)
파이썬에서는 아주 쉽게 큐와 스택을 사용할 수 있다.
특정하게 클래스를 만들 필요가 없다: 그냥 리스트 객체를 사용하면 된다.
스택(LIFO)이라면, append()로 쌓고 pop()으로 들어 낸다:
>>> a.append(11)
>>> a
[5, 8, 9, 11]
>>> a.pop()
11
>>> a.pop()
9
>>> a
[5, 8]
>>>
큐(FIFO)라면, append()로 큐에 넣고 pop(0)으로 큐에서 꺼낸다:
>>> a.append(11)
>>> a
[5, 8, 9, 11]
>>> a.pop(0)
5
>>> a.pop(0)
8
>>> a
[9, 11]
리스트가 종류에 관계없이 객체를 담을 수 있는 것처럼, 얼마든지 객체를 만들어 큐와 스택에 넣고 꺼낼 수 있다!
(Queue 모듈도 있지만, 이 모듈은 주로 쓰레드에 유용하다.)
여러 값을 돌려주는 함수
파이썬에 익숙하지 않다면, 함수가 리스트를 포함, 어떤 종류의 객체도 돌려줄 수 있다는 사실을 잊기가 쉽다.
이 덕분에 여러 값을 돌려주는 함수를 만들 수 있다. 이는 전형적으로 다른 언어라면 코드에 부담없이는 할 수 없는 것이다.
return (a+1,a*2,a*a)
>>> print myfunction(3)
(4, 6, 9)
다중 할당도 사용할 수 있다:
>>> print b
6
>>> print c
9
물론 함수는 객체를 어떤 방식/조합이든 상관없이 객체를 돌려줄 수 있다 (문자열, 정수, 리스트, 터플, 사전, 터플 리스트, 등등).
두 변수의 값을 교환하기
대부분의 언어에서 두 변수의 내용을 교환하려면 임시 변수를 사용해야 한다.
파이썬에서는 다중 할당으로 쉽게 처리할 수 있다.
>>> b=7
>>> (a,b)=(b,a)
>>> print a
7
>>> print b
3
파이썬에서 터플과 리스트 그리고 사전은 항상 함께 해야할 진정한 친구이다!
필독을 권함: 파이썬에 뛰어들기 (http://diveintopython.org/). 첫 장에 터플과 리스트 사전에 관한 멋진 자습서가 들어 있다. 그 책의 나머지도 꼭 읽어 보도록 하자 (책은 무료로 내려받을 수 있다).
리스트에서 원소 중복을 제거하기
임시로 리스트를 사전으로 변환하는 트릭을 사용한다:
>>> print dict().fromkeys(mylist).keys()
[8, 3, 12, 5]
>>>
파이썬 2.5라면, 집합(sets)을 사용할 수도 있다:
>>> print list(set(mylist))
[8, 3, 12, 5]
>>>
웹 페이지에서 모든 링크 얻는 법(1)
... 정규 표현식의 마법을 활용하면.
htmlSource = urllib.urlopen("http://sebsauvage.net/index.html").read(200000)
linksList = re.findall('<a href=(.*?)>.*?</a>',htmlSource)
for link in linksList:
print link
웹 페이지에서 모든 링크 얻는 법(2)
HTMLParser 모듈을 사용할 수도 있다.
class linkParser(HTMLParser.HTMLParser):
def __init__(self):
HTMLParser.HTMLParser.__init__(self)
self.links = []
def handle_starttag(self, tag, attrs):
if tag=='a':
self.links.append(dict(attrs)['href'])
htmlSource = urllib.urlopen("http://sebsauvage.net/index.html").read(200000)
p = linkParser()
p.feed(htmlSource)
for link in p.links:
print link
HTML 시작 태그를 만날 때마다, handle_starttag() 메쏘드가 호출된다.
예를 들어 <a href="http://google.com>는 다음handle_starttag(self,'A',[('href','http://google.com')]) 메쏘드가 촉발된다.
파이썬 매뉴얼에서 다른 handle_*() 메쏘드들도 참고하자.
(HTMLParser는 검증되지 않았음에 유의하자: 모양이-나쁜 HTML을 만나면 질식사한다. 이 경우, sgmllib모듈을 사용하고, 다시 정규 표현식으로 돌아가거나 BeautifulSoup를 사용하자.)
웹 페이지에서 모든 링크 얻는 법(3)
아직도 모자란다면?
Beautiful Soup는 HTML로부터 데이터를 잘 추출하는 파이썬 모듈이다.
Beautiful Soup의 메인 페이지에서 아주 나쁜 HTML 코드를 다루는 능력과 그의 단순함을 보여준다. 느리다는 단점이 있다.
http://www.crummy.com/software/BeautifulSoup/에서 얻을 수 있다
import BeautifulSoup
htmlSource = urllib.urlopen("http://sebsauvage.net/index.html").read(200000)
soup = BeautifulSoup.BeautifulSoup(htmlSource)
for item in soup.fetch('a'):
print item['href']
웹 페이지에서 모든 링크 얻는 법(4)
아직도 모자라신다면?
좋다. 여기 또 다른 방법이 있다:
보시라! 해석기도 없고 정규 표현식도 없다.
htmlSource = urllib.urlopen("http://sebsauvage.net/index.html").read(200000)
for chunk in htmlSource.lower().split('href=')[1:]:
indexes = [i for i in [chunk.find('"',1),chunk.find('>'),chunk.find(' ')] if i>-1]
print chunk[:min(indexes)]
인정한다. 조악하기 이를 데 없는 방법이다.
그러나 작동한다!
파일 압축하기/풀기
파일 압축하기:
f = zipfile.ZipFile('archive.zip','w',zipfile.ZIP_DEFLATED)
f.write('file_to_add.py')
f.close()
'w'를 'a'로 바꾸면 집 압축파일에 파일을 추가할 수 있다.
집 압축파일에서 파일을 풀기:
zfile = zipfile.ZipFile('archive.zip','r')
for filename in zfile.namelist():
data = zfile.read(filename)
file = open(filename, 'w+b')
file.write(data)
file.close()
디렉토리 안에 있는 파일을 (모든 서브디렉토리를) 모두 재귀적으로 압축하고 싶으면 :
f = zipfile.ZipFile('archive.zip','w',zipfile.ZIP_DEFLATED)
startdir = "c:\\mydirectory"
for dirpath, dirnames, filenames in os.walk(startdir):
for filename in filenames:
f.write(os.path.join(dirpath,filename))
f.close()
디렉토리의 내용을 나열하기
이렇게 하려면 필요에 따라 네 가지 방법이 있다.
listdir() 메쏘드는 한 디렉토리 안의 모든 파일을 담은 리스트를 돌려준다:
for filename in os.listdir(r'c:\windows'):
print filename
fnmatch() 모듈을 사용하면 파일 이름을 여과할 수 있다.
glob 모듈은 listdir()과 fnmatch()를 하나의 모듈 안에 싸넣은 것이다:
for filename in glob.glob(r'c:\windows\*.exe'):
print filename
서브디렉토리를 모을 필요가 있다면, os.path.walk()를 사용하자:
def processDirectory ( args, dirname, filenames ):
print 'Directory',dirname
for filename in filenames:
print ' File',filename
os.path.walk(r'c:\windows', processDirectory, None )
os.path.walk()는 역호출과 함께 작동한다: processDirectory()는 디렉토리를 만날 때마다 호출된다.dirname에는 디렉토리의 경로가 담긴다.filenames에는 이 디렉토리 안에 있는 파일이름들의 리스트가 담긴다.
os.walk()도 사용할 수 있는데, 이 메쏘드는 비-재귀적으로 작동하며 약간 더 이해하기가 쉽다.
for dirpath, dirnames, filenames in os.walk('c:\\winnt'):
print 'Directory', dirpath
for filename in filenames:
print ' File', filename
3 줄 웹서버
server = BaseHTTPServer.HTTPServer(('',80),SimpleHTTPServer.SimpleHTTPRequestHandler)
server.serve_forever()
이 웹서버는 현재 디렉토리에 있는 파일을 서비스한다. os.chdir()를 사용하여 디렉토리를 바꿀 수 있다.
이 트릭은 지역 네트워크에 있는 컴퓨터끼리 파일을 서비스하거나 전송하기에 편리하다.
이 웹서버는 아주 빠르지만, 한 번에 하나의 HTTP 요청만 서비스할 수 있다. 전송량이-많은 서버에는 사용하지 않는 것이 좋다.
수행성능을 개선하고 싶으면, 비동기 소켓(asyncore, Medusa...) 또는 다중-쓰레드 웹서버를 고려하자.
따로 예외를 만들고 일으키는 법
예외를 프로그램을 멈추게 만드는, 성가신 것으로 생각하지 말자. 예외는 같이 해야 할 친구이다. 예외는 좋은 것이다. 예외는 무언가 잘못되었음을, 무엇이 잘못되었는지 알려주는 전령이다. 그리고 try/except 블록에서 문제를 처리할 기회가 주어진다.
프로그램에서, 에러가 될만한 호출을 모두 잡아야 한다 (파일 접근, 네트워크 접속...).
따로 예외를 정의하여 클래스/모듈에 특정한 에러를 전송하는 것이 유용할 경우도 있다.
다음은 예외와 클래스를 정의하는 예이다 (예를 들어 myclass.py이라면):
pass
class myclass:
def __init__(self):
pass
def dosomething(self,i):
if i<0:
raise myexception, 'You made a mistake !'
(myexception는 초간단 예외이다: 아무것도 들어있지 않다. 그럼에도, 예외 그 자체가 메시지이므로 유용하다.)
이 클래스를 사용하면, 다음과 같이 할 수 있다:
myobject = myclass.myclass()
myobject.dosomething(-2)
이 프로그램을 실행하면, 다음과 같은 메시지를 받는다:
File "a.py", line 3, in ?
myobject.dosomething(-2)
File "myclass.py", line 9, in dosomething
raise myexception, 'You made a mistake !'
myclass.myexception: You made a mistake !
myclass는 뭔가 여러분이 잘못했다고 알려준다. 그래서 문제가 있을 경우, try/catch를 사용하는 편이 더 좋다:
myobject = myclass.myclass()
try:
myobject.dosomething(-2)
except myclass.myexception:
print 'oops ! myclass tells me I did something wrong.'
이제 좀 낫다 ! 문제가 있더라도 무언가 할 기회가 있다.
파이썬으로 Microsoft SQL 서버 스크립트하기
Microsoft SQL 서버가 있다면, 이런 상황을 맞이해 보았을 것이다. «Enterprise Manager (일명 MMC) 에서 모든 클릭을 스크립트할 수 있다면 얼마나 좋을까!».
할 수 있다 ! MMC로 할 수 있는 것이면 무엇이든 파이썬으로 스크립트할 수 있다.
win32all 파이썬 모듈만 있으면 파이썬에서 COM 객체에 접근할 수 있다 (http://starship.python.net/crew/mhammond/win32/ 참조)
(win32all 모듈은 ActiveState사의 파이썬 배포본으로도 제공된다:http://www.activestate.com/Products/ActivePython/)
일단 설치했으면, 그냥 SQL-DMO 객체를 사용하자.
예를 들어, 서버에 있는 데이터베이스 리스트를 얻자:
s = gencache.EnsureDispatch('SQLDMO.SQLServer')
s.Connect('servername','login','password')
for i in range(1,s.Databases.Count):
print s.Databases.Item(i).Name
또는 테이블 스크립트를 얻자:
script = database.Tables('CLIENTS').Script()
print script
SQL-DMO 문서는 MSDN에서 보실 수 있다:
- http://msdn.microsoft.com/library/en-us/sqldmo/dmoref_ob_s_7igk.asp
- http://msdn.microsoft.com/library/en-us/sqldmo/dmoref_ob_3tlx.asp
ODBC로 데이터베이스 접근하기
윈도우즈에서, ODBC는 거의 모든 데이터베이스에 쉽게 접근할 수 있도록 해준다. 별로 빠르지는 않지만, 문제가 안된다.
win32all 파이썬 모듈이 필요하다.
먼저, DSN을 만들자 (예: 'mydsn'), 다음:
conn = odbc.odbc('mydsn/login/password')
c = conn.cursor()
c.execute('select clientid, name, city from client')
print c.fetchall()
멋질 뿐만 아니라 쉽다 !
또 fetchone()나 fetchmany(n)를 사용하면 - 각각 - 하나 또는 n개의 행을 한 번에 가져올 수 있다.
주목하자 : 데이터세트가 너무 크면, 너무 열 개수가 많은 테이블에서 괴이한 그리고 예상치 못한 데이터 잘림을 경험한다. 이건 ODBC의 버그인가, 아니면 SQL Server ODBC 드라이버의 버그인가 ? 조사해 보아야 하겠다...
ADO로 데이터베이스 접근하기
윈도우즈에서, 데이터베이스에 접근하려면 ODBC 대신에 ADO도 사용할 수 있다 (Microsoft ActiveX Data Objects). 다음 코드는 ADO COM 객체를 사용하여 Microsoft SQL 서버 데이터베이스에 접근하여, 테이블을 열람하고 화면에 표시한다.
connexion = win32com.client.gencache.EnsureDispatch('ADODB.Connection')
connexion.Open("Provider='SQLOLEDB';Data Source='myserver';Initial Catalog='mydatabase';User ID='mylogin';Password='mypassword';")
recordset = connexion.Execute('SELECT clientid, clientName FROM clients')[0]
while not recordset.EOF:
print 'clientid=',recordset.Fields(0).Value,' client name=',recordset.Fields(1).Value
recordset.MoveNext()
connexion.Close()
ADO 문서는 MSDN을 참조하자: http://msdn.microsoft.com/library/en-us/ado270/htm/mdmscadoobjects.asp
윈도우즈에서 TinyWeb으로 CGI 처리하기
TinyWeb은 파일 하나로 구성된 윈도우즈용 웹 서버이다. (실행파일의 크기는 53 kb에 불과하다). 임시 웹 서버를 만들어 파일을 공유하는데 환상적이다. TinyWeb은 CGI도 서비스할 수 있다.
파이썬으로 CGI를 만들어 즐겨보자 !
먼저, TinyWeb을 얻어 설치해보자:
- TinyWeb은 http://www.ritlabs.com/tinyweb/에서 얻는다 (무료이며, 심지어 상업용으로 사용해도 좋다 !) 그리고
c:\아무디렉토리에나풀어놓자 (원하는 디렉토리는 어떤 것이든 상관없다). - 이 디렉토리에 "
www" 서브디렉토리를 만들자 index.html을www디렉토리에 만들자:<html><body>Hello, world !</body></html>- 서버를 실행하자:
tiny.exe c:\somedirectory\www
(반드시 절대 경로를 사용해야 한다) - 브라우저에
http://localhost를 지정하자
"Hello, world !"가 보이면, TinyWeb이 메모리에 잘 올라가 실행된다는 뜻이다.
CGI를 만들기 시작해 보자:
www디렉토리에 "cgi-bin" 서브디렉토리를 만들자.- 다음과 같이
hello.py를 만들자:print "Content-type: text/html"
print
print "Hello, this is Python talking !" .py파일을 클릭하면 윈도우즈가python.exe를 사용하도록 만들자.
(.py 파일 위에서 SHIFT+오른쪽클릭 하면, "Open with..."가 열리고, python.exe를 선택한 다음,
"Always use this program..." 박스에 체크하고, Ok를 클릭하자)- 브라우저에
http://localhost/cgi-bin/hello.py를 지정하자
(소스 코드가 아니라) "Hello, this is Python talking !"이 보일 것이다 .
그렇다면, 준비가 다 된 것이다 !
이제 멋지게 CGI를 만들어 볼 수 있다.
(이것이 작동하지 않는다면, python.exe를 가리키는 경로가 제대로 되었는지 확인해 보고 tinyweb의 명령줄에서 절대 경로를 사용했는지 확인하자.)
주목하자. 이는 아파치 아래의 mod_python만큼 빠르지는 않을 것이다 (TinyWeb은 파이썬 CGI의 요청마다 파이썬 인터프리리터의 실체를 새로 만들기 때문이다.). 그리하여 전송량이-많은 제품 서버에는 적당하지 않다. 그러나 소형 LAN이라면, 이와 같이 아주 간편하게 CGI를 서비스할 수 있다.
파이썬 문서에서 CGI 자습서를 참조하자.
- 힌트 1: TinySSL을 사용할 수 있다는 것도 잊지 말자. 이는 TinyWeb에서 SSL/HTTPS가 가능한 버전이다. 안전한 웹서버를 만드는데 정말 좋다 (특히 LAN 스니핑을 방지하는데 탁월하다. 인증을 요구할 수 있기 때문이다).
- 힌트 2: 파이썬 CGI를 py2exe로 포장하면, 파이썬이 설치되어 있지 않은 컴퓨터에서 CGI를 실행할 수 있다.
가벼운-힌트: 모든 exe/dll/pyd를 UPX로 압축하면, 전체 웹 서버와 그의 CGI를 플로피 디스크에 넣어 그것을 어디에서나 실행할 수 있다 ! (전형적인 Python 2.2로 "Hello, world !" CGI 예제와 TinyWeb를 합쳐서 기껏해야 375 kb에 불과하다!) - 힌트 3: (CGI가 아니라) 파일을 서비스하면, TinyWeb은 윈도우즈의 파일 확장자Content-type매핑을 사용한다 (예를 들어
.zip=application/x-zip-compressed).Content-type이 잘못이면, 다음 파일을 사용하여 교정할 수 있다: tinyweb.reg. - 힌트 4: 윈도우즈에서는 CGI로 올바르게 이진 파일을 전송하는 트릭이 있다: 표준출력(stdout) 모드를 텍스트(text) 모드로부터 이진(binary) 모드로 바꾸면 된다. 이는 윈도우즈에서만 요구된다:import sys(http://aspn.activestate.com/ASPN/Cookbook/Python/Recipe/65443/에서 가져 온 코드)
if sys.platform == "win32":
import os, msvcrt
msvcrt.setmode(sys.stdout.fileno(), os.O_BINARY)
파이썬 프로그램으로부터 .exe 파일 만들기
선(Sun)사의 Java나 마이크로소프트사의 .Net에서, 파이썬 프로그램을 배포하고 싶다면, 가상 머신도 함께 묶을 필요가 있다.
여러가지 선택이 있다: py2exe나 cx_Freeze 또는 pyInstaller중에 선택하면 된다.
py2exe
py2exe는 필요한 모든 파일을 모아서 파이썬이 설치되지 않은 컴퓨터에 프로그램을 배포하는 방법을 제공한다.
예를 들어, 윈도우즈에서 myprogram.py를 myprogram.exe로 바꾸고 싶다면, setup.py 파일을 다음과 같이 만들자:
import py2exe
setup(name="myprogram",scripts=["myprogram.py"],)
다음과 같이 실행한다:
py2exe는 모든 의존 파일을 모아서 \dist 서브디렉토리에 쓴다. 전형적으로 프로그램이 .exe,pythonXX.dll 그리고 보조적으로 .pyd 파일로 되어 있음을 볼 수 있다. 프로그램은 어떤 컴퓨터에서도 실행되며 심지어 파이썬이 설치되어 있지 않아도 된다. 이는 또한 CGI에도 작동한다.
(프로그램이 tkinter를 사용한다면, 트릭이 있음에 유의하자.)
힌트 : UPX를 사용하여 모든 dll/exe/pyd 파일을 압축하자. 이렇게 하면 파일 크기가 현격하게 줄어든다: upx --best *.dll *.exe *.pyd (전형적으로 python22.dll는 848 kb에서 324 kb로 줄어든다.)
버전 0.6.1 이후로, py2exe는 단일한 EXE 파일을 만들 수 있다. (pythonXX.dll 그리고 기타 파일이 EXE 파일 안으로 통합되어 들어간다).
# -*- coding: iso-8859-1 -*-
from distutils.core import setup
import py2exe
setup(
options = {"py2exe": {"compressed": 1, "optimize": 0, "bundle_files": 1, } },
zipfile = None,
console=["myprogram.py"]
)
cx_Freeze
cx_Freeze도 사용할 수 있는데, 이는 py2exe의 대안이다 (본인은 webGobbler에 이것을 사용했다).
또는 콘솔-없는 버전을 만들 수도 있다:
콘솔-없는 버전을 만들기 위한 팁: 무엇이든 인쇄(print) 하려고 하면, 짜증나게 에러 창이 뜬다. stdout 그리고 stderr가 존재하지 않기 때문이다 (cx_freeze Win32gui.exe 스터브는 에러 창을 화면에 표시한다).
프로그램을 GUI 모드 그리고 명령줄 모드에서 실행하고 싶다면 이는 고통스럽다.
안전하게 콘솔 출력을 비활성화하려면, 프로그램의 초반부에 다음과 같이 하자:
sys.stdout.write("\n")
sys.stdout.flush()
except IOError:
class dummyStream:
''' dummyStream은 아무것도 하지 않는 스트림처럼 행위한다. '''
def __init__(self): pass
def write(self,data): pass
def read(self,data): pass
def flush(self): pass
def close(self): pass
# 이제 모든 기본 스트림을 다음 dummyStream으로 방향전환한다:
sys.stdout = dummyStream()
sys.stderr = dummyStream()
sys.stdin = dummyStream()
sys.__stdout__ = dummyStream()
sys.__stderr__ = dummyStream()
sys.__stdin__ = dummyStream()
이런식으로 하면, 프로그램이 콘솔-없는 모드에서 시작하더라도, 작동할 것이다. 코드에 print 서술문이 있더라도 말이다.
그리고 명령줄 모드에서 실행된다면, 예와 같이 인쇄된다. (이는 기본적으로 webGobbler에서 시행한 방식이다.)
pyInstaller
pyInstaller는 McMillan 설치기를 재구현한 것이다. 한개짜리 실행파일도 만들 수 있다.
http://pyinstaller.hpcf.upr.edu/cgi-bin/trac.cgi/wiki에서 얻을 수 있다
pyInstaller를 pyinstaller_1.1 서브디렉토리에 푼 다음, 다음과 같이 한다:
(이렇게 한 번만 하면 된다.)
다음 프로그램을 위해 .spec 파일을 만든다:
다음 프로그램을 꾸려넣는다:
프로그램은 \distmyprogram 서브디렉토리에서 얻을 수 있다. (myprogram.exe, pythonXX.dll, MSVCR71.dll, etc.)
다음과 같이 여러 선택이 있다:
--onefile옵션은 한개짜리 EXE 파일을 만든다. 예:python pyinstaller_1.1\Makespec.py --onfile myprogram.py myprogram.spec이 EXE가 실행되면 모든 파일을 임시 디렉토리에 풀고, 그렇게 풀린 프로그램을 실행한다는 사실에 주의하자. 실행이 끝나면 모든 파일을 지워 버린다. 이런 행위를 좋아할 수도 싫어할 수도 있다.(나는 싫다).--noconsole옵션은 순수한 윈도우즈 실행파일을 생성한다 (콘솔 창이 없다).python pyinstaller_1.1\Makespec.py --noconsole myprogram.py myprogram.spec--tk옵션은 정말로 멋지다. tkinter에 필요한 모든 파일을 꾸려넣는다.
윈도우즈 레지스트리 읽기
key = _winreg.OpenKey(_winreg.HKEY_CURRENT_USER, 'Software\\Microsoft\\Internet Explorer', 0, _winreg.KEY_READ)
(value, valuetype) = _winreg.QueryValueEx(key, 'Download Directory')
print value
print valuetype
valuetype은 레지스트리 키의 유형이다. 자세한 것은 http://docs.python.org/lib/module--winreg.html를 참조하자
파이썬 프로그램의 수행성는 측정하는 법
파이썬에는 윤곽잡기 모듈이 따라온다: profile이 바로 그 모듈로서, 사용하기 쉽다.
예를 들어, myfunction()을 프로파일하고 싶다면, 다음과 같이 호출하는 대신에:
다음과 같이 하면 된다:
profile.run('myfunction()','myfunction.profile')
import pstats
pstats.Stats('myfunction.profile').sort_stats('time').print_stats()
다음과 같은 보고서가 화면에 표시될 것이다:
1822 function calls (1792 primitive calls) in 0.737 CPU seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.224 0.224 0.279 0.279 myprogram.py:512(compute)
10 0.078 0.008 0.078 0.008 myprogram.py:234(first)
1 0.077 0.077 0.502 0.502 myprogram.py:249(give_first)
1 0.051 0.051 0.051 0.051 myprogram.py:1315(give_last)
3 0.043 0.014 0.205 0.068 myprogram.py:107(sort)
1 0.039 0.039 0.039 0.039 myprogram.py:55(display)
139 0.034 0.000 0.106 0.001 myprogram.py:239(save)
139 0.030 0.000 0.072 0.001 myprogram.py:314(load)
...
이 보고서에 의하면, 각 함수/메쏘드마다:
- 얼마나 많이 호출되었는가 (
ncalls). - 함수에 소비된 총 시간 (서브-함수에 든 시간 제외) (
tottime) - 함수에 소비된 총 시간 (서브-함수에 든 시간 포함) (
cumtime) - 호출당 평균 시간 (
percall)
을 알 수 있다.
보시다시피, profile 모듈은 정확한 파일이름과 줄 그리고 함수 이름을 화면에 표시한다. 이는 귀중한 정보로서 프로그램에서 병목 지점을 찾는데 도움이 된다.
그러나 개발 단계에서 너무 이르게 최적화를 하려고 시도하지 말자. 이는 나쁘다 ! :-)
파이썬에는 비슷한 모듈로 이름이 hotspot이라는 모듈이 제공되는데, 이 모듈이 더 정확하지만 쓰레드와 잘 작동하지 않는다.
파이썬 프로그램의 속도 높이는 방법
파이썬 프로그램의 속도를 높이려면, 최적화나 알고리즘을 다시 디자인하는 방법을 넘어서는 것은 없다..
더 잘 할 수 없다고 생각되면, 언제나 Psyco를 사용하면 된다: Psyco는 파이썬을 위한 80x86-호환 시피유용 최적-시간 컴파일러이다. 아주 사용하기 쉬우며 즉시 x2에서 x100 배까지 속도를 높여준다.
- psyco를 파이썬 버전에 맞게 내려받자 (http://psyco.sourceforge.net/)
- 풀어서
\psyco디렉토리를 파이썬 site-packages 디렉토리에 복사하자 (윈도우즈라면c:\pythonXX\Lib\site-packages\psyco\와 같을 것이다)
다음, 다음을 프로그램의 시작 부분에 놓자:
psyco.full()
더 좋게 하자면:
import psyco
psyco.full()
except:
pass
이런 식으로, psyco가 설치되면 프로그램이 더 빨라진다.
psyco가 없으면, 프로그램은 예전 같이 실행된다.
(psyco가 아직도 충분하지 않다면, 너무 느린 코드를 C나 C++로 재작성하여 그것을 SWIG로 포장하면 된다 (http://swig.org/).)
주의: 코드를 디버깅하거나 윤곽잡기 또는 추적할 때, Psyco를 사용하지 말자. 결과가 정확하지 않고 이상한 행위를 경험할 수도 있다.
정규 표현식은 과도한 경우가 많다
포럼에서 텍스트 파일을 처리하고 싶어하는 사람을 도와준 적이 있다. 그는 텍스트에서 다음과 같은 "Two words"를 추출하고 싶어했다. 이 두 단어로 시작하는 모든 줄에서 말이다. 그는 먼저 다음과 같이 정규 표현식을 작성했다: r = re.compile("Two\sword\s(.*?)").
그의 문제는 다음과 같이 하는 것이 더 잘 해결되었을 것이다:
for line in file:
if line.startswith("Two words "):
print line[10:]
정규 표현식은 괴도한 경우가 많다. 언제나 정규 표현식이 최선의 선택은 아니다. 그 이유는:
- 과도한 부담이 수반된다:
- 정규 표현식을 컴파일해야 한다(
re.compile()). 즉 정규 표현식을 해석해서 그것을 상태 머신으로 변형해야 한다는 뜻이다. 이 때문에 CPU 시간이 소모된다. - 정규 표현식을 사용할 때, 텍스트에 대하여 상태 머신을 실행하는데, 이 때문에 상태 머신은 수 많은 규칙에 따라 상태를 바꾼다. 이 역시 CPU 시간을 잡아먹는다.
- 정규 표현식을 컴파일해야 한다(
- 정규 표현식은 실패에 안전하지 않다: 가끔 특정한 입력에 실패할 수 있다. "maximum recusion limit exceeded" 예외를 맞이할 수도 있다. 즉 모든
match()와search()그리고findall()메쏘드를try/except블록 안에 싸 넣어야 한다는 뜻이다. - 파이썬의 정수(
import this:-)에 의하면 «가독성이 중요하다». 가독성은 좋은 것이다. 정규 표현식은 읽고 디버그하고 수정하기가 급격하게 어려워진다.
게다가, find()나 rfind() 또는 startwith() 같은 문자열 메쏘드는 아주 빠르다. 정규 표현식에 비하면 훨씬 더 빠르다.
아무데나 정규 표현식을 사용하려고 하지 말자. 가끔은 문자열 연산을 여러 번 하는 편이 일을 더 빠르게 마칠 수도 있다.
또다른 파이썬 프로그램 실행하는 법
베이시안(Bayesian) 여과법
베이시안 여과법은 최신 스팸 여과법이다. 실제로 아주 효과가 있다 !
Reverend는 파이썬용 무료 베이시안(Bayesian) 모듈이다.http://divmod.org/trac/wiki/DivmodReverend에서 내려 받을 수 있다.
다음은 예이다: 텍스트의 언어를 인식하는 법.
먼저, 문장 몇 개를 가지고 훈련을 시킨다:
guesser = Bayes()
guesser.train('french','La souris est rentrée dans son trou.')
guesser.train('english','my tailor is rich.')
guesser.train('french','Je ne sais pas si je viendrai demain.')
guesser.train('english','I do not plan to update my website soon.')
이제 언어를 알아 맞혀 보자:
[('english', 0.99990000000000001), ('french', 9.9999999999988987e-005)]
베이시안 필터에 의하면: "99,99% 확률로 영어이다."
또다른 예를 시험해 보자:
[('french', 0.99990000000000001), ('english', 9.9999999999988987e-005)]
필터에 의하면: "99,99% 확률로 프랑스어이다."
나쁘지 않다. 그렇지 않은가 ?
동시에 여러 언어를 훈련시킬 수도 있다. 또한 어떤 종류의 텍스트를 분류하도록 훈련시킬 수도 있다.
Tkinter 그리고 cx_Freeze
(이 트릭은 py2exe에도 적용된다).
배포하기 위해 Tkinter 파이썬 프로그램을 cx_Freeze로 포장하고 싶다고 해 보자.
프로그램을 만든다:
# -*- coding: iso-8859-1 -*-
import Tkinter
class myApplication:
def __init__(self,root):
self.root = root
self.initializeGui()
def initializeGui(self):
Tkinter.Label(self.root,text="Hello, world").grid(column=0,row=0)
def main():
root = Tkinter.Tk()
root.title('My application')
app = myApplication(root)
root.mainloop()
if __name__ == "__main__":
main()
이 프로그램은 여러분의 컴퓨터에서 작동한다. 이제 cx_Freeeze로 포장해 보자:
프로그램(test.exe)으 실행시키면, 다음 에러를 맞이할 것이다:
사실, TKinter DLL을 복사해 줄 필요가 있다. 구축 배치 파일은 다음과 같이 된다:
copy C:\Python24\DLLs\tcl84.dll .\bin\
copy C:\Python24\DLLs\tk84.dll .\bin\
좋다. 이제 다시 구축해 보자.
EXE를 실행하면: 작동한다 !
EXE를 (파이썬이 설치되어 있지 않은) 또다른 컴퓨터에서 실행하면: 에러가 일어난다 !
File "cx_Freeze\initscripts\console.py", line 26, in ?
exec code in m.__dict__
File "test.py", line 20, in ?
File "test.py", line 14, in main
File "C:\Python24\Lib\lib-tk\Tkinter.py", line 1569, in __init__
_tkinter.TclError: Can't find a usable init.tcl in the following directories:
[...]
짜증난다. 그렇지 않은가?
실패하는 이유는 Tkinter가 실행시간 tcl 스크립트를 필요로 하기 때문이다. 이 스크립트들은 C:\Python24\tcl\tcl8.4 그리고 C:\Python24\tcl\tk8.4에 위치한다.
그래서 어플리케이션과 같은 디렉토리에 이 스크립트들을 복사하자.
구축 배치 파일은 다음과 같이 된다:
copy C:\Python24\DLLs\tcl84.dll .\bin\
copy C:\Python24\DLLs\tk84.dll .\bin\
xcopy /S /I /Y "C:\Python24\tcl\tcl8.4\*.*" "bin\libtcltk84\tcl8.4"
xcopy /S /I /Y "C:\Python24\tcl\tk8.4\*.*" "bin\libtcltk84\tk8.4"
그러나 또 프로그램에서 어디에서 tcl/tk 실행시간 스크립트를 얻을 지 알려줄 필요가 있다 (아래 볼드체(bold) 주의):
# -*- coding: iso-8859-1 -*-
import os, os.path
# 가능하면 지역 서브디렉토리로부터 tcl/tk 라이브러리를 얻는다.
if os.path.isdir('libtcltk84'):
os.environ['TCL_LIBRARY'] = 'libtcltk84\\tcl8.4'
os.environ['TK_LIBRARY'] = 'libtcltk84\\tk8.4'
import Tkinter
class myApplication:
def __init__(self,root):
self.root = root
self.initializeGui()
def initializeGui(self):
Tkinter.Label(self.root,text="Hello, world").grid(column=0,row=0)
def main():
root = Tkinter.Tk()
root.title('My application')
app = myApplication(root)
root.mainloop()
if __name__ == "__main__":
main()
이제 적절하게 Tkinter-가능 어플리케이션을 꾸려넣고 배포할 수 있다. (이 트릭은 webGobbler에 사용하였다.)
개선 점:
필요하지 않은 tcl/tk 스크립트는 제거할 수 있을 것이다. 예를 들어: (대략 500 kb에 이르는) bin\libtcltk84\tk8.4\demos는 오직 tk 데모 파일에 불과하다. 불필요하다.
이는 프로그램에서 어느 Tkinter 특징을 사용하는지에 달려 있다.
(cx_Freeze and - AFAIK - 다른 모든 패키지는 tcl/tk 의존성을 해결할 수 없다.)
몇가지 Tkinter 팁
Tkinter는 파이썬에 기본으로 제공되는 GUI 도구모음이다.
다음은 간단한 예이다:
class myApplication: #1
def __init__(self,root):
self.root = root #2
self.initialisation() #3
def initialisation(self): #3
Tkinter.Label(self.root,text="Hello, world !").grid(column=0,row=0) #4
def main(): #5
root = Tkinter.Tk()
root.title('My application')
app = myApplication(root)
root.mainloop()
if __name__ == "__main__":
main()
#1 : 클래스의 형태로 GUI를 코딩하는 것이 언제나 더 좋다. GUI 구성요소들을 더 쉽게 재사용할 수 있을 것이다.
#2 : 언제나 조상 클래스에 대한 참조점을 유지하자. 위젯을 추가할 때 필요할 것이다.
#3 : 위젯을 만들어 내는 코드는 확실하게 나머지 코드와 분리시켜 놓자. 관리하기가 더 쉬울 것이다.
#4 : .pack()을 사용하지 말자. 보통 산만하며 GUI를 확장하고 싶을 때 고통스럽다. grid()를 사용하면 위젯 요소들을 쉽게 이동시키고 배치할 수 있다. .pack()과 .grid()를 혼용하지 말자. 그렇지 않으면 어플리케이션이 경고없이 중지된다 CPU를 100% 소모하면서 말이다.
#5 : main() 함수를 정의해 두는 것이 언제나 좋은 생각이다. 이렇게 하면, 직접적으로 모듈을 실행할 수 있으므로 GUI 요소들을 테스트할 수 있다.
시간이 없는 고로, 이 권장 리스트는 webGobbler를 좀 더 경험한 후에 보충하겠다.
Tkinter 파일 대화상자
Tkinter는 파일이나 디렉토리 처리를 위한 여러 기본 대화상자가 제공된다. 아주 쉽게 사용할 수 있지만, 몇 가지 예제를 보여주는 것이 좋겠다:
디렉토리 선택하는 법:
import tkFileDialog
root = Tkinter.Tk()
directory = tkFileDialog.askdirectory(parent=root,initialdir="/",title='Please select a directory')
if len(directory) > 0:
print "You chose directory %s" % directory
열 파일을 선택한다 (askopenfile는 여러분을 위하여 파일을 열어준다. file은 보통의 파일 객체처럼 행위한다):
import tkFileDialog
root = Tkinter.Tk()
file = tkFileDialog.askopenfile(parent=root,mode='rb',title='Please select a file')
if file != None:
data = file.read()
file.close()
print "I got %d bytes from the file." % len(data)
다른 이름으로 저장... 대화상자:
import tkFileDialog
myFormats = [
('Windows Bitmap','*.bmp'),
('Portable Network Graphics','*.png'),
('JPEG / JFIF','*.jpg'),
('CompuServer GIF','*.gif'),
]
root = Tkinter.Tk()
filename = tkFileDialog.asksaveasfilename(parent=root,filetypes=myFormats,title="Save image as...")
if len(filename) > 0:
print "Now saving as %s" % (filename)
소스에 이진 파일 삽입하는 법
작은 파일은 소스에 삽입하는 것이 간편한 경우가 있다 (아이콘, 테스트 파일, 등등.)
파일(myimage.gif)을 하나 취해 base64로 변환하자 (선택적으로 zlib으로 압축할 수도 있다):
data = open('myimage.gif','rb').read()
print base64.encodestring(zlib.compress(data))
다음 프로그램으로 텍스트를 얻어서 소스 코드에 사용하자:
myFile = zlib.decompress(base64.decodestring("""
eJxz93SzsExUZlBn2MzA8P///zNnzvz79+/IgUMTJ05cu2aNaBmDzhIGHj7u58+fO11ksLO3Kyou
ikqIEvLkcYyxV/zJwsgABDogAmQGA8t/gROejlpLMuau+j+1QdQxk20xwzqhslmHH5/xC94Q58ST
72nRllBw7cUDHZYbL8VtLOYbP/b6LhXB7tAcfPCpHA/fSvcJb1jZWB9c2/3XLmQ+03mZBBP+GOak
/AAZGXPL1BJe39jqjoqEAhFr1fBi1dao9g4Ovjo+lh6GFDVWJqbisLKoCq5p1X5s/Jw9IenrFvUz
+mRXTeviY+4p2sKUflA1cjkX37TKWYwFzRpFYeqTs2fOqEuwXsfgOeGCfmZ57MP4WSpaZ0vSJy97
WPeY5ca8F1sYI5f5r2bjec+67nmaTcarm7+Z0hgY2Z7++fpCzHmBQCrPF94dAi/jj1oZt8R4qxsy
6liJX/UVyLjwoHFxFK/VMWbN90rNrLKMGQ7iQSc7mXgTkpwPXVp0mlWz/JVC4NK0s0zcDWkcFxxF
mrvdlBdOnBySvtNvq8SBFZo8rF2MvAIMoZoPmZrZPj2buEDr2isXi0V8egpelyUvbXNc7yVQkKgS
sM7g0KOr7kq3WRIkitSuRj1VXbSk8v4zh8fljqtOhyobP91izvh0c2hwqKz3jPaHhvMMXVQspYq8
aiV9ivkmHri5u2NH8fvPpVWuK65I3OMUX+f4Lee+3Hmfux96Vq5RVqxTN38YeK3wRbVz5v06FSYG
awWFgMzkktKiVIXkotTEktQUhaRKheDUpMTikszUPIVgx9AwR3dXBZvi1KTixNKyxPRUhcQSBSRe
Sn6JQl5qiZ2CrkJGSUmBlb4+QlIPKKGgAADBbgMp"""))
print "I have a file of %d bytes." % len(myFile)
예를 들어, 파이썬 이미지 라이브러리(PIL(Python Imaging Library))을 사용한다면, 다음 이미지를 직접적으로 열 수 있다:
myimage = Image.open(StringIO.StringIO(myFile))
myimage.show()
좋은 관례: try/except 비-표준 반입 서술문
프로그램에서 표준 파이썬 배포본에 있지 않은 모듈을 사용한다면, 사용자가 어느 모듈이 필요한지 어디에서 얻어야 하는지 식별하기가 아주 곤란하다.
간단한 try/except 서술문으로 고통을 덜어 주자. 모듈 이름을 알려주고 (항상 반입 서술문에서 언급된 이름과 같은 것은 아니다) 그리고 어디에서 얻어야 하는지 알려준다.
예제:
import win32com.client
except ImportError:
raise ImportError, 'This program requires the win32all extensions for Python. See http://starship.python.net/crew/mhammond/win32/'
좋은 관례: 읽기 가능한 객체
"클라이언트" 클래스를 정의하자. 클라이언트마다 이름과 번호가 있다.
def __init__(self,number,name):
self.number = number
self.name = name
이제 이 클래스의 실체를 생성하면 그리고 그것을 화면에 표시하면:
print my_client
그 결과는 다음과 같다:
상당히 정확하지만, 별로 명시적이지 못하다.
__repr__ 메쏘드를 추가하여 개선시켜 보자:
def __init__(self,number,name):
self.number = number
self.name = name
def __repr__(self):
return '<client id="%s" name="%s">' % (self.number, self.name)
다시 한 번 해 보자:
print my_client
다음이 결과이다:
아 !
훨씬 좋다. 이제 이 객체는 의미가 있다.
디버깅이나 로깅에 훨씬 더 좋다.
심지어 이를, 예를 들어 클라이언트 디렉토리 같은 복합 객체에 적용해도 된다:
def __init__(self):
self.clients = []
def addClient(self, client):
self.clients.append(client)
def __repr__(self):
lines = []
lines.append("<directory>")
for client in self.clients:
lines.append(" "+repr(client))
lines.append("</directory>")
return "\n".join(lignes)
다음 디렉토리를 만든다. 그리고 클라이언트를 이 디렉토리에 추가한다:
my_directory.addClient( client(5,"Smith") )
my_directory.addClient( client(12,"Doe") )
print my_directory
결과는 다음과 같다:
<client id="5" name="Smith">
<client id="12" name="Doe">
</directory>
훨씬 더 좋다. 그렇지 않은가?
이 트릭은 - 파이썬에만 국한되지 않고 - 디버깅과 로깅에 편리하다.
예를 들어, 프로그램이 성장하면, try/except 블록의 except 절에서 디버깅의 목적으로 그 객체의 상태를 파일에 기록할 수 있다.
좋은 관례: 빈줄-점검 없이 read()
파일이나 소켓을 읽을 때, 단순히 다음과 같이 .read()를 사용하는 경우가 있다:
file = open("a_file.dat","rb")
data = file.read()
file.close()
# URL로부터 읽는다:
import urllib
url = urllib.urlopen("http://sebsauvage.net")
html = url.read()
url.close()
그러나 파일이 40 Gb가 넘어가거나, 웹 사이트가 끊임-없이 데이터를 전송하면 어떻게 되는가?
프로그램은 시스템 메모리를 모두 먹어치우고, 느려져서 꾸물꾸물 기어가다가 결국 시스템 충돌이 일어날 것이다.
언제나 read()에 제한을 두어야 한다.
예를 들어, 나는 10 Mb가 넘는 파일을 처리하지 않을 것이고,200 kb가 넘는 HTML 페이지는 읽지 않을 생각이다. 그래서 다음과 같이 작성한다:
file = open("a_file.dat","rb")
data = file.read(10000000)
file.close()
# URL로부터 읽는다:
import urllib
url = urllib.urlopen("http://sebsauvage.net")
html = url.read(200000)
url.close()
이런식으로 나는 버그투성이 또는 악성인 외부 데이터 소스로부터 안전을 지킨다.
통제하지 못하는 데이터를 다룰 때는 언제나 조심하자!
...에, 마지막으로, 여러분의 데이터에도 주의를 기울이자.
그렇지 않으면 별별 일이 다 일어난다.
1.7이 1.7과 다르다고요 ?
이는 흔히 신참 프로그래머가 흔히 빠지는 함정이다:
부동소수점수 1.7을 보면, 단지 컴퓨터 메모리에 저장된 이진 데이터의 텍스트 표현을 볼 뿐이다.
날짜를 사용한다면, 다음과 같이 :
>>> print datetime.datetime.now()
2006-03-21 15:23:20.904000
>>>
"2006-03-21 15:23:20.904000"은 날짜가 아니다 . 날짜의 텍스트 표현이다 (진짜 날짜는 컴퓨터 메모리에 있는 이진 데이터이다 ).print 서술문은 별거 아닌 듯 보이지만, 그렇지 않다. 복잡한 작업을 거쳐 다양한 이진 데이터 포맷을 인간이-읽을 수 있는 표현으로 만들어 낸다. 이 작업은 단순한 정수조차도 간단한 작업이 아니다.
이 때문에 함정에 빠지는데, 예를 들어:
b = 0.9 + 0.8 # 이는 1.7이 되어야 한다.
print a
print b
if a == b:
print "a and b are equal."
else:
print "a and b are different !"
이 코드가 무엇을 인쇄할 것이라고 생각하는가 ? "a와 b가 같은가?".
틀렸다!
1.7
a and b are different !
이거 어떻게 된 건가?
어떻게 1.7이 1.7과 다를 수 있지 ?
두 개의 "1.7"은 그저 숫자의 텍스트 표현일 뿐임을 상기하자. 둘은 거의 1.7에 가까울 뿐이다.
프로그램에 의하면 둘은 다른데 그 이유는 a와 b가 이진 수준에서 다르기 때문이다 .
그들의 텍스트 표현만 같을 뿐이다.
그리하여 부동소수점 수를 비교하려면, 다음 트릭을 사용하자:
print "a and b are equal."
else:
print "a and b are different !"
또는 다음과 같이 해도 된다:
print "a and b are equal."
else:
print "a and b are different !"
왜 0.9+0.8이 1.7과 다른가 ?
컴퓨터는 오직 비트만 다룰 수 있기 때문에, 정확하게 모든 숫자를 이진 형태로 표현할 수 없기 때문이다.
컴퓨터는 0.5 (이진값으로 0.1이다), 또는 0.125 (이진값으로 0.001이다) 같은 값들을 저장하는데 좋다.
그러나 0.3 값은 정확하게 저장할 수 없다. (왜냐하면 이진값으로 정확하게 0.3을 표현할 수 없기 때문이다).
그리하여, a=1.7을 하자마자, a에 1.7이 담기는 것이 아니라, 십진수 1.7의 대략적인 이진 값이 담긴다.
사용자의 홈 디렉토리 경로 얻는 법
프로그램용으로 환경설정 파일을 저장하거나 열람할 수 있으면 편리하다.
print os.path.expanduser('~')
이 방법은 윈도우즈에서도 작동함을 주목하자. 멋지다 !
(사용자의 "Document and settings" 폴더를 가리키거나, 또는 사용자가 가지고 있다면 네트워크 폴더를 가리키기도 한다.)
파이썬의 가상 기계
파이썬은 - 자바나 마이크로소프트 .Net 같이 - 가상 머신이 있다.
파이썬은 특정한 바이트코드가 있다. 인텔 80386이나 펜티엄 머신 언어 같은 기계어이지만, 이를 실행할 수 있는 물리적인 마이크로프로세서는 없다.
바이트코드는 마이크로프로세서를 흉내내는 프로그램 안에서 실행된다: 즉 가상 머신 안에서 실행된다.
이는 자바와 .Net도 마찬가지이다. 자바의 가상 머신은 이름이 JVM (Java Virtual Machine)이고, .Net의 가상 머신은 CLR (Common Language Runtime)이라고 부른다
예를 하나 들어 보자: mymodule.py
print "I have ",a
b = a * 3
if b<50:
b = b + 77
return b
이 프로그램은 숫자를 하나 취해, 그것을 화면에 보여주고, 거기에 3을 곱한 다음, 만약 그 결과가 50 보다 작을 경우 77을 더해서, 돌려준다. (솔직히, 이거 좀 이상하기는 하다.)
시험해 보자:
Python 2.4.2 (#67, Sep 28 2005, 12:41:11) [MSC v.1310 32 bit (Intel)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import mymodule
>>> print mymodule.myfunction(5)
I have 5
92
>>>
좋다, 간단하다.
mymodule.pyc 파일이 나타난게 보이는가? 이것이 바로 모듈을 "컴파일한 버전"으로서 파이썬 바이트코드이다. 이 파일에는 파이썬 가상 머신을 위한 지시어들이 담겨 있다.
.pyc 파일은 모듈이 반입될 때마다 파이썬에 의하여 자동으로 생성된다.
파이썬은 원한다면 직접 .pyc 파일을 반입할 수도 있다. 심지어 .py 파일이 없어도 .pyc를 실행할 수 있다.
.pyc 파일을 지우면, .py 파일로부터 다시 만들어진다.
.py 소스를 갱신하면, 파이썬은 이 변화를 탐지해서 자동으로 그에 맞게 .pyc 파일을 갱신한다.
.pyc 바이트코드를 들여다 보고 어떻게 생겼는지 보고 싶은가 ?
아주 쉽다:
>>> dis.dis(mymodule.myfunction)
2 0 LOAD_CONST 1 ('I have')
3 PRINT_ITEM
4 LOAD_FAST 0 (a)
7 PRINT_ITEM
8 PRINT_NEWLINE
3 9 LOAD_FAST 0 (a)
12 LOAD_CONST 2 (3)
15 BINARY_MULTIPLY
16 STORE_FAST 1 (b)
4 19 LOAD_FAST 1 (b)
22 LOAD_CONST 3 (50)
25 COMPARE_OP 0 (<)
28 JUMP_IF_FALSE 14 (to 45)
31 POP_TOP
5 32 LOAD_FAST 1 (b)
35 LOAD_CONST 4 (77)
38 BINARY_ADD
39 STORE_FAST 1 (b)
42 JUMP_FORWARD 1 (to 46)
>> 45 POP_TOP
6 >> 46 LOAD_FAST 1 (b)
49 RETURN_VALUE
>>>
가상 머신의 지시어들(LOAD_CONST, PRINT_ITEM, COMPARE_OP...)과 그들의 연산자를 볼 수 있다 (0은 변수 a가 가리키는 것이고, 1은 변수 b가 가리키는 것이다...)
예를 들어 소스에서 3번 줄은 다음과 같은데: b = a * 3
파이썬 바이트코드로 이를 번역하면 다음과 같다:
12 LOAD_CONST 2 (3) # 값 3을 스택에 적재한다
15 BINARY_MULTIPLY # 그들을 곱한다
16 STORE_FAST 1 (b) # 그 결과를 변수 b에 저장한다
파이썬은 또한 코드를 최적화하려고 시도한다.
예를 들어 다음 "I have" 문자열은 두 번째 줄 이후로는 사용되지 않는다. 그래서 파이썬은 변수 b에 대하여 그 문자열의 주소를 사용하기로 결정한다 (1).
파이썬 가상 머신이 지원하는 지시어 목록은http://www.python.org/doc/current/lib/bytecodes.html에 있다.
SQLite - 단순하게 만든 데이터베이스
SQLite은 엄청난 데이터베이스 엔진이다. 진심이다.
몇가지 단점이 있다:
- 병행 접근용으로 디자인되어 있지 않다 (쓰는 동안 데이터베이스 전체가 잠긴다).
- 지역적으로만 작동한다 (네트워크 서비스가 없다. 물론 sqlrelay 같은 걸 사용할 수 있다).
- 외래 키를 처리하지 못한다.
- 권한 관리가 없다 (grant/revoke).
장점은 다음과 같다:
- 아주 빠르다 (대부분의 연산에서 mySQL보다 빠르다).
- SQL-92 표준을 대부분 준수한다.
- 서비스를 설치할 필요가 없다.
- 데이터베이스 관리를 수행할 필요가 없다.
- 사용되지 않을 때에는 컴퓨터 메모리와 CPU를 소비하지 않는다.
- SQLite 데이터베이스는 간결하다
- 1 데이터베이스 = 1 파일 (손쉽게 이동/배치/백업/전송/이메일 처리를 할 수 있다).
- SQLite 데이터베이스는 프랫폼마다 호환성이 있다 (Windows, MacOS, Linux, PDA...)
- SQLite는 ACID이다 (컴퓨터가 꺼지거나 충돌할 경우에도 데이터 일관성이 보장된다)
- 트랜잭션을 지원한다
- 필드에 Nulls, 정수, 실수 (부동소수점수), 텍스트 또는 이진데이터(blob)를 저장할 수 있다).
- 2 테라-바이트까지 데이터를 처리할 수 있다 (그렇지만 12 Gb를 넘어서면 권장하지 않는다).
- 메모리-내 데이터베이스처럼 작동한다 (수행성능이 눈부시다!)
SQLite는 아주 빠르고, 아주 간결하며, 쉽게 사용할 수 있다. 지역 데이터 처리를 위해서라면 신이 주신 선물이다 (웹사이트, 데이터 분석, 등등.).
물론... 무료일 뿐만 아니라, 또한 공개 영역에 위치한다 (GPL 라이센스로 고민할 필요도 없다).
아주 마음에 든다.
SQLite 엔진은 다양한 언어로부터 접근이 가능하다. (그리하여 SQLite 데이터베이스는 또한 프로그램 사이에 다양한 언어로 작성된 복잡한 데이터 세트를 교환하기에 훌륭한 방법이기도 하다. 심지어 숫치/텍스트/이진 데이터로 서로 섞여 있어도 된다. base64-인코드된 데이터로 특별한 파일 포맷이나 복잡한 XML 스키마를 고안할 필요도 없다.)
SQLite는 파이썬 2.5에 임베드되어 있다.
파이썬 2.4 이전이라면, 따로 설치해야 한다: http://initd.org/tracker/pysqlite
다음은 기본적인 사용법이다:
# -*- coding: iso-8859-1 -*-
from sqlite3 import dbapi2 as sqlite
# 데이터베이스를 만든다:
con = sqlite.connect('mydatabase.db3')
cur = con.cursor()
# 테이블을 만든다:
cur.execute('create table clients (id INT PRIMARY KEY, name CHAR(60))')
# 줄 하나를 삽입한다:
client = (5,"John Smith")
cur.execute("insert into clients (id, name) values (?, ?)", client )
con.commit()
# 한 번에 여러 줄을 삽입한다:
clients = [ (7,"Ella Fitzgerald"),
(8,"Louis Armstrong"),
(9,"Miles Davis")
]
cur.executemany("insert into clients (id, name) values (?, ?)", clients )
con.commit()
cur.close()
con.close()
이제, 데이터베이스를 사용해 보자:
# -*- coding: iso-8859-1 -*-
from sqlite3 import dbapi2 as sqlite
# 기존의 데이터베이스에 접속한다
con = sqlite.connect('mydatabase.db3')
cur = con.cursor()
# 행단위로 얻는다
print "Row by row:"
cur.execute('select id, name from clients order by name;')
row = cur.fetchone()
while row:
print row
row = cur.fetchone()
# 한번에 모든 행을 얻는다:
print "All rows at once:"
cur.execute('select id, name from clients order by name;')
print cur.fetchall()
cur.close()
con.close()
다음과 같이 출력된다:
(7, u'Ella Fitzgerald')
(5, u'John Smith')
(8, u'Louis Armstrong')
(9, u'Miles Davis')
All rows at once:
[(7, u'Ella Fitzgerald'), (5, u'John Smith'), (8, u'Louis Armstrong'), (9, u'Miles Davis')]
데이터베이스를 만들고 기존의 데이터베이스에 접속하는 것은 같은 명령을 사용한다(sqlite.connect()).
윈도우즈에는 SQLite 데이터베이스를 관리하기 위한 멋진 프리웨어가 있다: SQLiteSpy가 그것이다. (http://www.zeitungsjunge.de/delphi/sqlitespy/)
힌트 1: sqlite.connect(':memory:')를 사용하면, 이는 메모리-내 데이터베이스를 생성한다. 디스크에 접근하지 않으므로, 이렇게 하면 아주 데이터베이스가 빠르다.
(그러나 데이터를 처리하기 위한 메모리가 충분히 있는지 확인하자.)
힌트 2: 프로그램을 Python 2.5 그리고 Python 2.4+pySqlLite와 호환되게 하려면, 다음과 같이 하자:
from sqlite3 import dbapi2 as sqlite # 파이썬 2.5 용
except ImportError:
pass
if not sqlite:
try:
from pysqlite2 import dbapi2 as sqlite # 파이썬 2.4 용 그리고 pySqlLite
except ImportError:
pass
if not sqlite: # 모듈 반입에 성공하지 못하면, 에러를 일으킨다.
raise ImportError, "This module requires either: Python 2.5 or Python 2.4 with the pySqlLite module (http://initd.org/tracker/pysqlite)"
# 그렇다면 사용한다
con = sqlite.connect("mydatabase.db3")
...
이런 식으로, sqlite는 파이썬 2.5나 2.4에서 실행될 때마다 적절하게 반입된다.
링크:
- pySQLite 홈페이지: http://initd.org/tracker/pysqlite
- SQLite 홈페이지 (데이터베이스 엔진 자체에 관한 정보가 풍부하다): http://www.sqlite.org/
파이썬에 뛰어들기
파이썬으로 프로그래밍을 하고 있는가?
그렇다면 반드시 파이썬에 뛰어들기라는 책을 읽어 보아야 하다.
이 책은 무료이다.
가서 읽어 보자.
이 책을 읽지 못했다면 품위있는 파이썬 프로그래밍은 상상할 수 없다.
최소한 내려 받자...
...이제!
이는 필독서이다.
이 책은 다양한 포맷으로 무료로 얻을 수 있다 (HTML, PDF, Word 97...).
풍부한 정보와 좋은 관례, 아이디어, 함정 그리고 조각코드가 풍성하다. 클래스, 데이터유형, 내부검사, 예외, HTML/XML 처리, 유닛 테스트, 웹 서비스, 리팩토링 등등에 관하여 말이다.
이 책을 읽어 본 것에 대하여 언젠가는 감사할 날이 올 것이다. 내 말을 믿어라.
윈도우즈에서 상호배제(mutex) 만드는 법
webGobbler에서 상호배제를 사용하였다. webGobbler가 여전히 실행중인지 InnoSetup 언인스톨러가 알도록 하기 위하여 말이다 (그리고 프로그램이 실행중일 경우 언인스톨 되면 안된다).
이것은 InnoSetup의 편리한 특징이다.
try:
import ctypes
except ImportError:
CTYPES_AVAILABLE = False
WEBGOBBLER_MUTEX = None
if CTYPES_AVAILABLE and sys.platform=="win32":
try:
WEBGOBBLER_MUTEX=ctypes.windll.kernel32.CreateMutexA(None,False,"sebsauvage_net_webGobbler_running")
except:
pass
except:pass를 수행한다. 왜냐하면 상호배제가 생성되지 못하더라도, 나의 프로그램에서는 큰 문제가 아니기 때문이다 (그것은 언인스톨러가 처리할 문제일 뿐이다).
여러분은 상황에 따라 다를 수 있다.
이 상호배제는 파이썬 프로그램이 종료하면 자동으로 파괴된다.
urllib2 그리고 프록시
urllib2로 프록시를 사용할 수 있다.
proxy_info = { 'host' : 'proxy.myisp.com',
'port' : 3128
}
# 프록시를 위하여 처리자를 만든다
proxy_support = urllib2.ProxyHandler({"http" : "http://%(host)s:%(port)d" % proxy_info})
# 이 처리자를 사용하는 개방자(opener)를 만든다:
opener = urllib2.build_opener(proxy_support)
# 다음 이 개방자를 urllib2를 위한 기본 개방자로 설치한다:
urllib2.install_opener(opener)
# 이제 HTTP 요청을 전송할 수 있다:
htmlpage = urllib2.urlopen("http://sebsauvage.net/").read(200000)
이 트릭이 멋진 이유는 전체 프로그램을 위하여 프록시 매개변수들을 설정해 주기 때문이다.
프록시에 인증이 필요하면, 역시 그것도 할 수 있다!
'port' : 3128,
'user' : 'John Doe',
'pass' : 'mysecret007'
}
proxy_support = urllib2.ProxyHandler({"http" : "http://%(user)s:%(pass)s@%(host)s:%(port)d" % proxy_info})
opener = urllib2.build_opener(proxy_support)
urllib2.install_opener(opener)
htmlpage = urllib2.urlopen("http://sebsauvage.net/").read(200000)
(이 코드 조각은 주로 http://groups.google.com/groups?selm=mailman.983901970.11969.python-list%40python.org에서 영감을 얻었다. )
파이썬 2.4.2부터, urllib2는 오직 다음의 프록시 인증 방법만 지원한다: Basic 그리고 Digest.
프록시가 (윈도우즈/IE-종속적인) NTLM을 사용하면, 운이 따르지 않는 것이다.
이 트릭 외에도, 더 간단하게 프록시를 설정하는 방법이 있다:
os.environ['HTTP_PROXY'] = 'http://proxy.myisp.com:3128'
os.environ['FTP_PROXY']로도 똑같이 할 수 있다.
HTTP 요청에 알맞은 사용자-중개자
파이썬 프로그램에서 HTTP 요청을 전송할 경우, 네티켓에 의하면 적절하게 자신의 신분을 밝혀야 한다.
기본으로, 파이썬은 사용자-중개자를 다음과 같이 사용한다: Python-urllib/1.16이 그것인데,
이를 바꾸고 싶다면,
다음은 urllib2을 가지고 바꾸는 방법이다:
request = urllib2.Request('http://sebsauvage.net', None, request_headers)
urlfile = urllib2.urlopen(request)
제일 중요한 규칙으로서:
- 사용자-중개자에서 사용하는 프로그램의 이름이 정말로 유일한 것인지 확인하자 (구글에서 검색!).
- 다음 형태를 채용하자:
applicationName/version, 예를 들어webGobbler/1.2.4. - 프로그램이 웹 사이트를 긁어온다면, 반드시 로봇 규칙(robot rules)을 존중해야 한다.
- 언제나 한계를 두어 읽자. (예를 들어
.read(200000)와 같이 해야지, 달랑.read()만 쓰면 안된다). - 네트워크 타임아웃을 지혜롭게 선택하자. 전체 프로그램에 타임아웃을 설정하기 위하여 다음 코드를 사용할 수 있다:socket.setdefaulttimeout(60) # 60 초면 시간초과.
urllib2로 에러 처리하는 법
urllib/urllib2를 사용하고 있고 404에러와 기타 HTTP 에러를 점검하고 싶다면?
다음은 그 트릭이다:
urlfile = urllib2.urlopen('http://sebsauvage.net/nonexistingpage.html')
except urllib2.HTTPError, exc:
if exc.code == 404:
print "Not found !"
else:
print "HTTP request failed with error %d (%s)" % (exc.code, exc.msg)
except urllib2.URLError, exc:
print "Failed because:", exc.reason
이런 식으로 404에러와 기타 HTTP 에러 코드를 점검할 수 있다.
urllib2는 2xx 그리고 3xx 코드에서는 예외를 일으키지 않는다. urllib2.HTTPError 예외는 4xx 그리고 5xx 코드에서 일어난다 (이는 예상된 행위이다).
(또 주목하자. HTTP 30x 리다이렉션은 자동으로 그리고 투명하게 urllib2가 처리한다.)
urllib2: 무엇을 받고 있는 거지?
HTTP 요청을 전송하면, html이나 이미지 또는 비디오 등등이 돌아온다.
어떤 경우에는 받고 있는 데이터의 유형이 예상대로 인지 점검해야 한다.
받고 있는 문서의 유형을 점검하려면, MIME 유형을 보자 (Content-type) 헤더:
print "Document type is", urlfile.info().getheader("Content-Type","")
이는 다음과 같이 출력된다:
경고: 쌍반점 다음에 정보가 있을 수 있다. 예를 들어:
그래서 언제나 다음과 같이 하면:
오직 "text/html" 부분만 얻을 수 있다.
주목하자. .info()는 또한 다른 HTTP 응답 헤더도 돌려준다:
print urlfile.info()
다음과 같이 인쇄된다:
Content-Type: text/html; charset=iso-8859-1
Server: Apache
X-Powered-By: PHP/5.1.2-1.dotdeb.2
Connection: close
방대한 XLS (Excel) 파일을 읽고(쓰기)
나는 한 프로젝트에서 거대한 XLS 파일을 읽어야 했다.
물론 COM 호출을 통하여 모든 셀 내용에 접근할 수 있지만, 너무 느리다.
간단한 트릭이 있다: 그냥 엑셀에게 XLS 파일을 열어 그것을 CSV로 저장해 달라고 요구한 다음, 파이썬의 CSV 모듈을 사용하여 그 파일을 읽어 들이면 된다!
이 방법이 방대한 XLS 데이터 파일을 읽는 가장 빠른 방법이다.
import win32com.client
filename = 'myfile.xls'
filepath = os.path.abspath(filename) # 언제나 확실하게 절대 경로를 사용하자!
# 엑셀을 시작하고 XLS 파일을 연다:
excel = win32com.client.Dispatch('Excel.Application')
excel.Visible = True
workbook = excel.Workbooks.Open(filepath)
# CSV로 저장한다:
xlCSVWindows =0x17 # from enum XlFileFormat
workbook.SaveAs(Filename=filepath+".csv",FileFormat=xlCSVWindows)
# 작업책과 엑셀을 닫는다.
workbook.Close(SaveChanges=False)
excel.Quit()
힌트: 이 트릭을 다른 곳에서도 사용할 수 있다. (파이썬으로 CSV를 만들고, 엑셀을 열어) 방대한 양의 데이터를 엑셀 안으로 반입한다. 이 방법은 COM 호출을 통하여 데이터 셀을 채우는 것보다 훨씬 더 빠르다.
힌트: excel.Workbooks.Open()을 사용할 때,os.path.abspath()로 언제나 확실하게 절대 경로를 사용하자.
힌트: 또한 엑셀에게 HTML로 저장해 달라고 요청한 다음, 그 HTML을 htmllib이나 sgmllib 또는 BeautifulSoup로 해석할 수도 있다. 포맷팅, 컬러, 셀 스팬, 문서 저자나 심지어 수식에 이르기까지 더 많은 정보를 얻을 수 있을 것이다. !
힌트: 엑셀 VBA 문서는 *.chm을 C:\Program Files\Microsoft Office\에서 검색해 보자
예를 들어: 엑셀 2000이라면, C:\Program Files\Microsoft Office\Office\1036\VBAXL9.CHM이 도움말이다.
힌트: VBA 도움말 파일을 헤매지 않고서 한 행위에 상응하는 VBA 코드를 찾고 싶다면, 그냥 그 행위에 대한 매크로를 기록한 다음 열어 보자!
이렇게 하면 자동으로 VBA 코드가 만들어진다 (손쉽게 파이썬으로 변환할 수 있다).
이 트릭을 보여주는 비디오를 만들었다 (프랑스어에요, 죄송):http://sebsauvage.net/temp/wink/excel_vbarecord.html
힌트: 가끔, 엑셀 상수가 필요하다. 상수 목록을 얻으려면:
- makepy.py를 실행한다 (예- C:\Python24\Lib\site-packages\win32com\client\makepy.py)
- 목록에서, "Microsoft Excel 9.0 Object Library (1.3)" (뭐 그런거)를 선택해서 ok를 클릭한다.
- C:\Python24\Lib\site-packages\win32com\gen_py\ 디렉토리를 들여다 본다.
그 라이브러리를 감싼 포장자가 보일 것이다 (예를 들어 00020813-0000-0000-C000-000000000046x0x1x3.py) - 이 파일을 연다: Excel 상수와 그의 값이 들어있다 (그것을 코드에 붙여 넣으면 된다.)
예를 들어:xlCSVMSDOS =0x18 # from enum XlFileFormat
xlCSVWindows =0x17 # from enum XlFileFormat
작은-힌트 2: CSS 스타일을 사용하여 여러 셀을 포맷하거나 색상을 설정할 수도 있다. 그냥 생성된 HTML에 <style> 스타일 시트를 포함시켜 두면 된다.
작은-힌트 3: CSS를 사용하면, 심지어 셀 포맷도 할 수 있다 (텍스트, 숫자, 등등). 예를 들어,
<style><!--.mystyle{mso-number-format:"\@";}--></style> 이라면 <td class=mystyle>25</td>를 사용하여 셀을 강제로 텍스트 셀로 만들 수 있다 (쓸모가 있다. 예를 들어, 엑셀이 국제 전화 번호를 계산하지 못하도록 막는데 말이다 - 멍청이 어플리케이션 !)또는
mso-number-format:"0\.000";로 하면 3자리 정밀도로 숫자 포맷을 강제할 수 있다. 스택 추적 저장하기
가끔 어플리케이션을 만들 때, 디버깅 목적을 위해 스택 추적을 로그 파일에 쏟아 넣는 것이 편리한 경우가 있다.
다음은 그 방법이다:
def fifths(a):
return 5/a
def myfunction(value):
b = fifths(value) * 100
try:
print myfunction(0)
except Exception, ex:
logfile = open('mylog.log','a')
traceback.print_exc(file=logfile)
logfile.close()
print "Oops ! Something went wrong. Please look in the log file."
이 프로그램을 실행하고 나면, mylog.log에 담긴 내용은 다음과 같다:
File "a.py", line 10, in ?
print myfunction(0)
File "a.py", line 7, in myfunction
b = fifths(value) * 100
File "a.py", line 4, in fifths
return 5/a
ZeroDivisionError: integer division or modulo by zero
힌트: 그냥 간단하게 traceback.print_exc(file=sys.stdout)을 사용하여 스택추적으로 화면에 인쇄할 수도 있다.
힌트: 이 트릭을 이것과 혼용하면 시간을 절약해 줄 수 있다. 상세한 에러 메시지 덕분에, 버그를 더 쉽게 찾을 수 있다.
경고 여과하기
가끔, 파이썬은 경고를 화면에 표시한다.
유용하며 당연히 조심해야 하겠지만, 가끔 비활성화하고 싶은 경우가 있다.
다음은 경고를 여과하는 법이다:
warnings.filterwarnings(action = 'ignore',message='.*?no locals\(\) in functions bound by Psyco')
(이 특정한 Psyco 경고를 걸러내는데 사용한다.)message는 정규 표현식이다.
너무 많이 걷어내지 않도록 조심하자. 중요한 정보가 버려질 수도 있으니까 말이다.
PIL을 사용하여 이미지를 JPEG로 저장하는 법
PIL (Python Imaging Library)은 이미지 처리에 아주 좋은 그래픽 라이브러리이다 (이 라이브러리를webGobbler에 사용하였다).
다음은 Image 객체를 JPEG로 저장하는 법이다.
쉬워 보이지만, 잠깐...
(myimage는 Image PIL 객체라고 간주한다.)
문자와 인코딩
(이 글의 프랑스어 번역본이 있다: http://sebsauvage.net/python/charsets_et_encoding.html )
텍스트 = ASCII = 8 bits = 문자당 1 바이트라고 알고 있다면, 잘못 알고 계신 것이다.
시야를 넓혀보자.
개발자라면 꼭 알아야 할 것이 있다. 그렇지 않고 잘 이해하지 못한다면 언젠가 한 번 물릴 날이 반드시 온다:
좋다. 이렇게 말해 보자:
여러분은 컴퓨터가 거대한 바보 머신이라고 알고 있다. 컴퓨터는 알파벳 관하여 심지어 십진수 조차도전혀 알지 못한다. 컴퓨터는 비트만 이해한다.
그래서 기호 'a'나 물음표 '?'를 사용할 경우, 컴퓨터를 위하여 이런 심볼들의 이진 표현을 만들어 주어야 한다.
그것이 심볼들을 컴퓨터의 메모리에 저장하는 유일한 방법이다.
문자 세트
먼저, 각 심볼에 대하여 어느 숫자를 사용할지 결정해야 한다. 그것이 간단한 문자표이다.
보통은 ASCII라고 간주된다.
ASCII에서 기호 'a'는 숫자 97이고, 물음표 '?'는 숫자 67이다.
그러나 ASCII는 국제 표준과는 아주 멀다.
다른 문자 세트가 엄청 많다. 예를 들어 EBCDIC, 러시아 문자를 위한 KOI8-R, 라틴어를 위한 ISO-8852-1 (예를 들어, 액센트 문자들), 중국어용 Big5, 일본어용 Shift_JIS, 등등. 나라마다 문화권마다 언어마다 자신만의 문자 세트를 발전시켜왔다. 정말로 혼란스럽다.
국제적으로 이 모든 것을 표준하려는 노력이 있다: UNICODE가 바로 그것이다.
유니코드는 거대한 표로서 어느 숫자가 어느 심볼을 사용해야 하는지 알려준다.
예를 들자면:
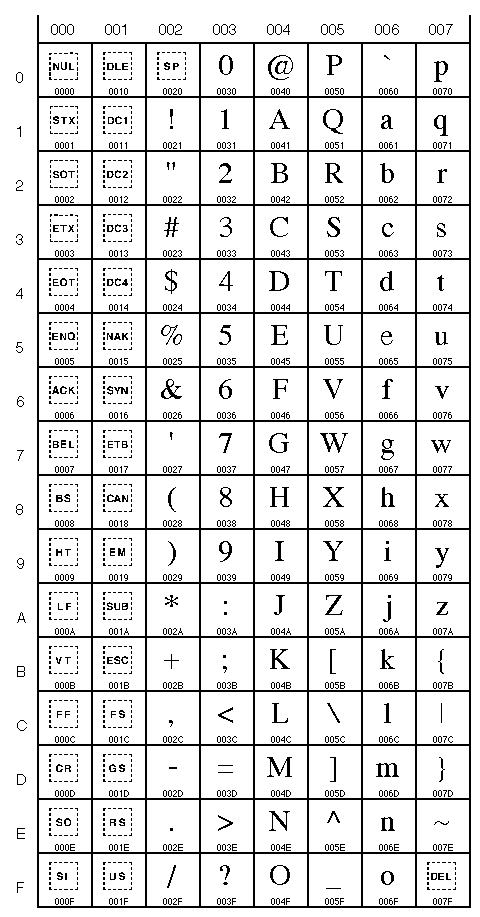 | 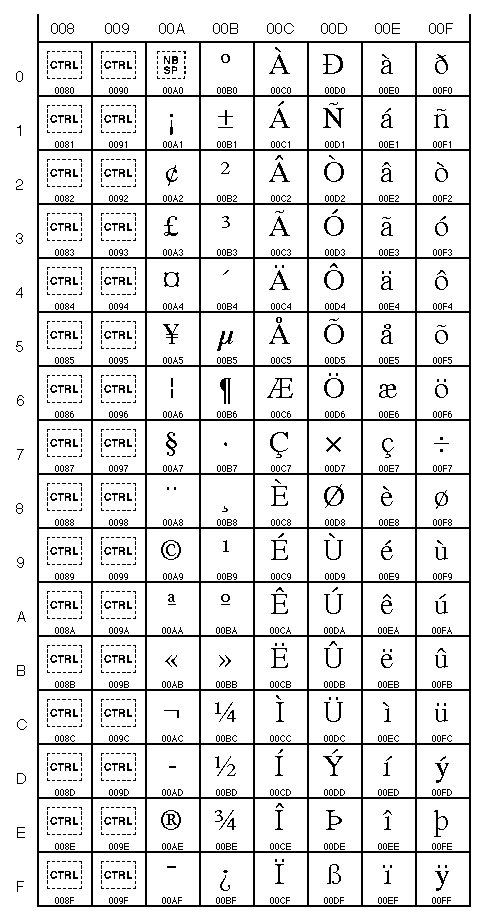 |  |  |
| Unicode table 0000 to 007F (0 to 127) (Latin characters) | Unicode table 0080 to 00FF (128 to 255) (Latin characters, including accented characters) | Unicode table 0900 to 097F (2304 to 2431) (devanagari) | Unicode table 1100 to 117F (4352 to 4479) (hangul jamo) |
그래서 "bébé" (불어로 아기)라는 단어는 다음 숫자로 번역된다: 98 233 98 233 (또는 16비트 십육진수로 0062 00E9 0062 00E9으로 번역됨).
인코딩
이제 이 모든 숫자를 확보하였으므로, 각 숫자에 대한 이진 표현을 찾아야 한다.
ASCII는 단순하게 매핑한다: 1 ASCII code (0...127) = 1 byte (8 or 7 bits). ASCII에 대해서는 문제가 없는데, ASCII는 오직 0에서 127까지의 숫자만 사용하기 때문이다. 바이트 단위에는 꼭 맞는다.
그러나 유니코드와 기타 문자 세트에 대해서는 문제가 된다: 8 비트로는 충분하지 않다. 이 문자세트는 다른 인코딩을 요구한다.
대부분의 문자세트는 멀티-바이트 인코딩을 사용한다 (문자가 여러 바이트로 표현된다).
유니코드에는 여러 인코딩이 있다. 첫 번째 인코딩은 날 16 비트 유니코드로서 문자당 16 비트 (2 바이트)를 사용한다.
그러나 대부분의 텍스트에서 유니코드 테이블의 하위 부분(0에서 127까지의 코드)만 사용하기 때문에, 공간 낭비가 심하다.
때문에 UTF-8이 고안되었다.
똑똑하게도: 0에서 127까지의 코드에는 그냥 문자당 1 바이트를 사용한다. ASCII와 똑 같다.
특별한 좀 희귀한 문자(128 to 2047)가 필요하다면, 2 바이트를 사용한다.
좀 더 특정한 문자(2048 to 65535)가 필요하다면, 3바이트를 사용한다.
등등.
| 유니코드 값 (십육진수로) | 비트로 화면출력 |
| 00000000 to 0000007F | 0xxxxxxx |
| 00000080 to 000007FF | 110xxxxx 10xxxxxx |
| 00000800 to 0000FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 00010000 to 001FFFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 00200000 to 03FFFFFF | 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 04000000 to 7FFFFFFF | 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
그리하여 대부분의 라틴 텍스트에 이것은 ASCII처럼 공간-절약적이지만, 원하면 무엇이든 특수한 유니코드 문자를 사용할 수 있다.
어떻게 그런가?
이 모든 것을 요약해 보자
| 심볼 | → | 숫자 | → | 비트 |
| 문자세트(charset) | 인코딩(encoding) |
문자세트(charset)는 각 심볼에 대하여 어느 숫자를 사용해야 하는지 알려준다.
인코딩(encoding)은 이 숫자들을 어떻게 비트로 인코드해야 하는지 알려준다.
한가지 간단한 예제는 다음과 같다:
| é | → | 233 | → | C3 A9 |
| 유니코드로 | UTF-8로 |
예를 들어, "bébé"라는 단어는 (프랑스어로 아기):
| bébé | → | 98 233 98 233 | → | 62 C3 A9 62 C3 A9 |
| 유니코드로 | UTF-8로 |
62 C3 A9 62 C3 A9라는 비트를 받았는데 인코딩(encoding)과 문자세트(charset)를 모른다면, 이것은 아무 쓸모가 없다.
아무 실마리도 없는 프로그래머라면 있는 그대로 이 비트들을 화면에 표시할 것이다: 
그렇다면 이런 의문이 들 것이다: "왜 저런 이상한 문자들을 얻게 되는가?".
이 글을 읽고 있는 여러분은 실마리가 주어진 셈이다.
텍스트를 전송한다면, 반드시 언제나 어느 문자세트/인코딩이 사용되었는지 알려주어야 한다.
그 때문에 많은 웹 페이지가 깨진다: 자신의 문자세트/인코딩을 알려주지 않기 때문이다.
이 경우 모든 브라우저가 그 문자세트를 추측한다는 사실을 알고 계시는가?
그건 나쁜 일이다.
웹페이지마다 자신의 인코딩을 HTTP 헤더나 HTML 헤더 자체에 지녀야 한다. 예를 들어:<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1">
힌트: 어떤 인코딩은 특정 문자세트에 종속된다. 예를 들어, UTF-8은 오직 유니코드에만 사용된다. 그래서 UTF-8로 인코드된 데이터를 받는다면, 그의 문자세트는 유니코드이다.
파이썬과 유니코드
파이썬은 직접적으로 유니코드와 UTF-8을 지원한다.
가능하면 UTF-8을 사용하자.
프로그램에서 부드럽게 국제 문자를 지원할 것이다.
먼저, 언제나 파이썬 소스에 사용하는 문자세트/인코딩을 명시해야 한다. 예를 들어:
# -*- coding: iso-8859-1 -*-
다음으로, 유니코드 문자열을 프로그램에 사용하자 (앞에 'u'를 사용하면 된다):
bestString = u"Good unicode string."
anotherGoodString = u"Ma vie, mon \u0153uvre."
( \u0153은 유니코드 문자로 "œ"이다. (0153이 "œ"에 대한 코드임). "œ" 문자는 차트에서 latin-1 섹션에 있다: http://www.unicode.org/charts/ )
표준 문자열을 유니코드로 변환하려면, 다음과 같이 하자:
또는 다음과 같이 하면 된다.
유니코드 문자열을 특정한 문자세트로 변환하려면:
파이썬이 지원하는 문자세트/인코딩 목록은 http://docs.python.org/lib/standard-encodings.html에 있다.
인쇄(print)할 때 잊지 말자. 콘솔(stdout)의 문자세트를 사용해야 한다. 가끔 유니코드 문자열을 인쇄하지 못할 경우가 있는데, 그 이유는 그 문자열에 운영체제 시스템 콘솔의 문자세트에 없는 유니코드 문자가 들어 있기 때문이다.
다시 한 번 강조하겠다: 간단한 print 지시어도 실패할 수 있다 .
예를 들어, 프랑스어로 "œuvre"는:
>>> print a
Traceback (most recent call last):
File "<stdin>", line 1, in ?
File "c:\python24\lib\encodings\cp437.py", line 18, in encode
return codecs.charmap_encode(input,errors,encoding_map)
UnicodeEncodeError: 'charmap' codec can't encode character u'\u0153' in position 0: character maps to <undefined>
파이썬은 유니코드 문자 153 (œ)이 운영체게 시스템 콘솔이 사용하는 문자세트에 없다고 알려준다.
어느 문자세트를 콘솔이 지원하는지 알아 보려면, 다음과 같이 해 보면 된다:
>>> print sys.stdout.encoding
cp437
그래서 에러 없이 확실하게 인쇄하려면, 다음과 같이 할 수 있다:
>>> a = u'\u0153uvre'
>>> print a.encode(sys.stdout.encoding,'replace')
?uvre
>>>
콘솔에 표시되지 못하는 유니코드 문자는 '?'로 변환된다.
특별히 주의: 외부 소스를 다룰 때 (파일, 데이터베이스, stdint/stdout/stderr, Windows COM이나 레지스트리 같은 API 등등) 주의하자: 이 중에는 유니코드로 통신하지 않는 것이 있다. 오직 특별한 몇몇 문자세트로만 통신한다. 그에 맞게 적절하게 유니코드 사이를 변환해 주어야 한다.
예를 들어, 유니코드 문자열을 UTF-8 인코드된 파일로 변환하려면, 다음과 같이 하면 된다:
>>> file = open('myfile.txt','w')
>>> file.write( a.encode('utf-8') )
>>> file.close()
같은 파일을 읽는 방법은:
>>> print file.read()
œuvre
>>>
이런... 보시다시피 여기에 문제가 있다. 파일을 열었지만, 읽을 때 인코딩을 지정하지 않았다. 그 때문에 이런 "┼ô" 쓰레기를 받는다 (이는 UTF-8 코드이다).
UTF-8로 디코드해 보자:
>>> print repr( file.read().decode('utf-8') )
u'\u0153uvre'
>>>
올바르게 받았다. 바로 원하던 "œuvre" 단어이다.
콘솔에서 \u0153 문자를 지원하지 않았던 사실을 기억하시는지? (그 때문에 repr()을 사용했다.)
그래서 그 문자열을 콘솔에서 지원하는 문자세트로 인코드해 보자:
>>> file=open('myfile.txt','r')
>>> print file.read().decode('utf-8').encode(sys.stdout.encoding,'replace')
?uvre
>>>
물론, 이는 귀찮아 보인다.
그러나 3가지 모드 사이를 변환하고 있다는 것을 잊지 말자 : UTF-8 (입력 파일)과 Unicode (파이썬 객체) 그리고 cp437 (출력 콘솔 문자세트).
| UTF-8 | → | Unicode | → | cp437 |
| 입력 파일. | .decode('utf-8') | 파이썬 유니코드 문자열. | .encode('cp437') | 콘솔 |
그 때문에 명시적으로 인코딩 사이를 변환해야 한다.
명시적인 것이 묵시적인 것보다 더 좋다.
참조 링크:
- http://www.joelonsoftware.com/articles/Unicode.html
- http://www.tbray.org/ongoing/When/200x/2003/04/06/Unicode
- http://www.tbray.org/ongoing/When/200x/2003/04/26/UTF
- http://www.cl.cam.ac.uk/~mgk25/unicode.html
- http://www.unicode.org/
순회하기(Iterating)
더 짧은 구문
다른 언어로부터 오셨다면, 이런 구조를 사용하고 싶은 유혹이 들 것이다.
예를 들어, 테이블의 요소들을 반복할 경우, 아마도 인덱스를 사용하여 순회하려고 할 것이다:
for i in range(0,len(countries)):
print countries[i]
또는
i = 0
while i<len(countries):
print countries[i]
i = i+1
반복자를 사용하는 편이 더 좋다:
for country in countries:
print country
같은 일을 한다. 그러나:
- 변수를 하나 절약했다 (i).
- 코드가 더 간결하다.
- 더 읽기 좋다.
"for country in countries"는 거의 영어나 다름 없다.
텍스트 파일로부터 줄을 읽는 것같과 같이, 다른 것들도 마찬가지이다. 그래서 다음과 같이 하는 대신에:
for line in file.readlines():
print line
file.close()
다음과 같이 한다:
for line in file:
print line
file.close()
이런 종류의 구조는 코드를 더 짧게 그리고 더 가독성이 좋게 유지하는데 도움이 될 수 있다.
여러 원소를 가지고 반복하는 법
여러 항목을 한 번에 반복하는 것도 쉽다.
('Germany',114,'Wolf Spietzer'),
('Belgium',227,'Serge Ressant')
]
for (country,nbclients,manager) in data:
print manager,'manages',nbclients,'clients in',country
이는 사전(해시테이블)에도 적용된다. 예를 들어, 다음과 같은 사전도 반복할 수 있다:
for country in data: # 이는 country in data.keys()과 동등하다
print 'We have',data[country],'clients in',country
그러나 이런 식으로 하는 것이 더 좋다:
for (country,nbclients) in data.items():
print 'We have',nbclients,'clients in',country
각 항목마다 해시를 하나씩 절약하기 때문이다.
반복자 만들기(iterators)
쉽게 자신만의 반복자를 만들 수 있다.
예를 들어, 클라이언트 파일이 있다고 해 보자:
France 523
Germany 114
Spain 127
Belgium 227
그리고 이 파일 포맷을 읽을 수 있는 클래스가 필요하다. 나라와 클라이언트의 수를 돌려주어야 한다.
clientFileReader 클래스를 만든다:
def __init__(self,filename):
self.file=open(filename,'r')
self.file.readline() # 첫 줄은 버린다.
def close(self):
self.file.close()
def __iter__(self):
return self
def next(self):
line = self.file.readline()
if not line:
raise StopIteration()
return ( line[:13], int(line[13:]) )
반복자를 만들려면:
- 반복자를 돌려주는
__iter__()메쏘드를 만든다 (우연하게도 우리가 정의하고 있는 것이다 !) - 반복자는 다음 항목을 돌려주는
next()메쏘드가 있어야 한다. next()메쏘드는 더 이상 데이터가 없을 경우StopIteration()예외를 일으켜야 한다.
이와 같이 쉽다!
그러면 파일 판독기를 다음과 같이 사용하기만 하면 된다:
for (country,nbclients) in clientFile:
print 'We have',nbclients,'clients in',country
clientFile.close()
이해되시는지?
"for (country,nbclients) in clientFile:"는 높은 수준의 구조로서 코드를 훨씬 더 가독성이 좋게 만들고 그 밑에 깔린 파일 포맷의 복잡성을 감추어 준다.
메인 회돌이에서 파일 줄을 잘라내는 것보다 이것이 훨씬 더 낫다.
명령-줄 해석하는 법
명령-줄을 손수 해석하려고 시도하지 말자(sys.argv). 명령-줄을 해석하는 일은 보기보다 쉽지 않다.
파이썬에는 명령-줄 해석을 위해 전문적으로 두 개의 모듈이 있다: getopt와 optparse가 그것이다.
일을 아주 잘 한다 (예를 들어, 매개변수 인용과 같은 세속적인 일들을 책임지고 처리해 준다).
optparse는 새로운, 더 파이썬스러운 OO 모듈이다. 그러나 본인은 getopt를 선호하는 경우가 많다. 이 두 모듈을 살펴보겠다.
좋다. 텍스트 파일에서 모든 줄을 반대로 뒤집는 프로그램을 만들어 보자.
프로그램은 다음과 같은 조건을 갖추어야 한다:
- 필수 인자:
file, 처리할 파일 지정. - 값을 가진 선택적 매개변수:
-o는 출력 파일을 지정한다 (다음과 같이-o myoutputfile.txt) - 값이 없는 선택적 매개변수:
-c는 모든 기호를 대문자로 만든다. - 선택적 매개변수:
-h는 프로그램의 도움말을 화면에 표시한다.
getopt
먼저 getopt로 시작해 보자:
import getopt
if __name__ == "__main__":
opts, args = None, None
try:
opts, args = getopt.getopt(sys.argv[1:], "hco:",["help", "capitalize","output="])
except getopt.GetoptError, e:
raise 'Unknown argument "%s" in command-line.' % e.opt
for option, value in opts:
if option in ('-h','--help'):
print 'You asked for the program help.'
sys.exit(0)
if option in ('-c','--capitalize'):
print "You used the --capitalize option !"
elif option in ('-o','--output'):
print "You used the --output option with value",value
# 필수 인자를 확실하게 설정한다 (file)
if len(args) != 1:
print 'You must specify one file to process. Use -h for help.'
sys.exit(1)
print "The file to process is",args[0]
# 나머지 코드는 여기에 둔다...
세부사항:
getopt.getopt()는 명령-줄을 해석한다:sys.argv[1:]은 프로그램 이름을 건너뛴다 (프로그램 이름은sys.argv[0]이다)"hco:"는 가능한 옵션 목록을 돌려준다(-h와-c그리고-o). 쌍점(:)은-o이 값을 요구한다고 알려준다.["help", "capitalize","output="]으로 사용자는 기다란 옵션을 사용할 수 있다 (--help/--capitalize/--output).
사용자는 명령줄에서 짧은 옵션과 긴 옵션을 섞어 쓸 수 있다. 예를 들어:reverse --capitalise -o output.txt myfile.txt
for회돌이는 모든 옵션을 점검한다.- 전형적으로 이 회돌이 안에서 명령-줄 옵션에 맞게 프로그램 옵션을 수정한다.
--help는 도움말 페이지를 화면에 보여주고 종료한다 (sys.exit(0)).
if len(args)!=1은 확실하게 필수 인자(file)가 제공되었는지 점검하는데 사용된다. 여러 인자를 허용하기로 (또는 허용하지 않기로) 결정할 수 있다.
명령줄에서 프로그램을 사용해 보자:
You used the --capitalize option !
You used the --output option with value output.txt
The file to process is myfile.txt
도움을 요청할 수도 있다:
You asked for the program help.
(물론, 여기에 진짜 유용한 프로그램 정보를 보여주어야 할 것이다.)
optparse
같은 일을 optparse로 해 보자:
import optparse
if __name__ == "__main__":
parser = optparse.OptionParser()
parser.add_option("-c","--capitalize",action="store_true",dest="capitalize")
parser.add_option("-o","--output",action="store",type="string",dest="outputFilename")
(options, args) = parser.parse_args()
if options.capitalize:
print "You used the --capitalize option !"
if options.outputFilename:
print "You used the --output option with value",options.outputFilename
# 필수 인자를 확실하게 설정한다 (file)
if len(args) != 1:
print 'You must specify one file to process. Use -h for help.'
sys.exit(1)
print "The file to process is",args[0]
# 나머지 코드는 여기에 둔다...
크게 다르지 않다. 그러나:
- 먼저 해석기(
optparse.OptionParser())를 만들고, 옵션을 이 해석기에 추가한다 (parser.add_option(...)) 다음 명령-줄을 해석해 달라고 요구한다 (parser.parse_args()). - 옵션 -c는 값을 받지 않는다. 그저
action="store_true"로-c의 존재를 기록할 뿐이다.dest="capitalize"는 이 옵션을 해석기의capitalize속성에 저장한다. -o에 대하여, 문자열(string)을 지정하여 해석기의 outputFilename 속성에 저장한다.
- 옵션 -c는 값을 받지 않는다. 그저
- 나중에
options.capitalize와options.outputFilename을 통하여 우리의 옵션을 접근해 보겠다. 회돌이는 전혀 없다. args는 여전히file인자를 돌려준다.
시험해 보자:
You used the --capitalize option !
You used the --output option with value output.txt
The file to process is myfile.txt
잘 작동한다. 도움말을 요청해 보자:
usage: reverse2.py [options]
options:
-h, --help show this help message and exit
-c, --capitalize
-o OUTPUTFILENAME, --output=OUTPUTFILENAME
그러나 눈치채셨는가?--help 옵션을 만들지 않았다!
그런데도 작동한다!
그것은 optparse가 여러분을 대신하여 만들어 주기 때문이다.
심지어 help 매개변수로 도움말을 옵션에 추가할 수도 있다. 예를 들어:
parser.add_option("-o","--output",action="store",type="string",dest="outputFilename",help="Write output to a file")
이의 결과는 다음과 같다:
usage: reverse2.py [options]
options:
-h, --help show this help message and exit
-c, --capitalize Capitalize all letters
-o OUTPUTFILENAME, --output=OUTPUTFILENAME
Write output to a file
도움말이 자동으로 작성되었다.
optparse는 상당히 유연하다. 심지어 도움말 페이지를 맞춤 재단하는 등등으로 확장할 수도 있다.
파이썬에서 AutoIt 사용하기
AutoIt은 윈도우즈용 무료 스크립팅 언어이다: 버튼을 클릭할 수 있고, 키눌림을 전송할 수 있으며, 윈도우즈를 기다릴 수 있다.
날 Win32 API를 사용하면 파이썬에서도 똑 같이 할 수 있지만, 좀 고통스럽다. AutoIt COM 인터페이스를 사용하는 편이 훨씬 더 쉽다.
예제: 노트패드를 실행시키고 텍스트를 좀 전송해 보자.
autoit = win32com.client.Dispatch("AutoItX3.Control")
autoit.Run("notepad.exe")
autoit.AutoItSetOption("WinTitleMatchMode", 4)
autoit.WinWait("classname=Notepad")
autoit.send("Hello, world.")
(창을 그의 클래스로 ("classname=Notepad") 일치시켰다. 그의 타이틀이 아님에 주목하자. 왜냐하면 제목은 창마다 다르기 때문이다 (영어, 불어, 독어, 등등))
물론, 이는 그저 COM 호출일 뿐이다. 특별한 것은 없다. 그러나 AutoIt은 간편하다.
AutoIt COM 문서는 C:\Program Files\AutoIt3\AutoItX\AutoItX.chm에 있다
COM 콘트롤은 C:\Program Files\AutoIt3\AutoItX\AutoItX3.dll이다
이 COM 콘트롤을 먼저 등록해야 사용할 수 있다는 것을 잊지 말자 (명령-줄로: regsvr32 AutoItX3.dll).
등록되어 있지 않을 경우 본인은 다음 코드를 사용하여 자동으로 COM 콘트롤을 등록한다:
# Win32 COM 클라이언트를 반입한다
try:
import win32com.client
except ImportError:
raise ImportError, 'This program requires the pywin32 extensions for Python. See http://starship.python.net/crew/mhammond/win32/'
import pywintypes # COM 에러를 처리하기 위하여.
# AutoIT을 반입한다 (첫 시도)
autoit = None
try:
autoit = win32com.client.Dispatch("AutoItX3.Control")
except pywintypes.com_error:
# 실체화할 수 없으면, 다시 COM 콘트롤을 등록하려고 시도한다:
os.system("regsvr32 /s AutoItX3.dll")
# AutoIT을 반입한다 (필요하면 두 번째 시도)
if not autoit:
try:
autoit = win32com.client.Dispatch("AutoItX3.Control")
except pywintypes.com_error:
raise ImportError, "Could not instanciate AutoIT COM module because",e
if not autoit:
print "Could not instanciate AutoIT COM module."
sys.exit(1)
# 이제 AutoIT 반입됨, Notepad를 시작하고 텍스트를 써본다:
autoit.Run("notepad.exe")
autoit.AutoItSetOption("WinTitleMatchMode", 4)
autoit.WinWait("classname=Notepad")
autoit.send("Hello, world.")
메인에는 무엇이 있는가
파이썬을 가지고 놀아 보았다면, 틀림없이 이런 이상한 파이썬 관용구를 보았을 것이다:
이게 무엇인가?
파이썬 프로그램은 (적어도) 두 가지 방식으로 사용된다:
- 직접적으로 실행되는 방법:
python mymodule.py - 반입되어 실행되는 방법:
import mymodule
if __name__=="__main__" 아래에 있는 코드는 오직 그 모듈이 직접적으로 실행되는 경우에만 실행된다.
이 모듈을 반입하더라도, 실행되지 않는다.
이 방법은 사용처가 많다. 예를 들어:
- 메인에서 명령줄을 해석해서 메쏘드/힘수를 호출한다. 그래서 모듈은 명령줄에서 사용이 가능하다.
- 메인에서 유닛 테스트(unittest)를 실행한다. 그래서 모듈은 실행되면 자가-테스트를 수행한다.
- 메인에서 예제 코드를 실행한다 (예를 들어, tkinter 위젯에 대하여).
예제: 명령-줄 해석하는 법
HTML 페이지에서 모든 링크를 추출하는 모듈을 작성하여 보자. 그리고 이 모듈에 메인을 추가하여 보자:
class linkextractor:
def __init__(self,htmlPage):
self.htmlcode = htmlPage
def getLinks(self):
linksList = re.findall('<a href=(.*?)>.*?</a>',self.htmlcode)
links = []
for link in linksList:
if link.startswith('"'): link=link[1:] # 인용부호를 제거한다
if link.endswith('"'): link=link[:-1]
links.append(link)
return links
if __name__ == "__main__":
import sys,getopt
opts, args = getopt.getopt(sys.argv[1:],"")
if len(args) != 1:
print "You must specify a file to process."
sys.exit(1)
print "Linkextractor is processing %s..." % args[0]
file = open(args[0],"rb")
htmlpage = file.read(500000)
file.close()
le = linkextractor(htmlpage)
print le.getLinks()
- class linkextractor에 프로그램 로직이 담겨 있다.
- main에서는 오직 명령-줄만 해석하여, 지정된 파일을 읽어 이 파일을 linkextractor를 사용하여 처리한다.
명령 줄에서 실행하면 이 클래스를 사용할 수 있다:
Linkextractor is processing myPage.html...
[...]
또는 반입하면 또다른 파이썬 프로그램에서 사용할 수 있다:
htmlSource = urllib.urlopen("http://sebsauvage.net/index.html").read(200000)
le = linkextractor.linkextractor(htmlSource)
print le.getLinks()
이 경우, 메인은 실행되지 않는다.
명령-줄에서 클래스를 직접적으로 사용할 수 있으면 아주 편리하다.
예제: 자가-테스트 실행하기
다음 유닛에 대하여 자가-테스트를 작성할 수도 있다:
class linkextractor:
def __init__(self,htmlPage):
self.htmlcode = htmlPage
def getLinks(self):
linksList = re.findall('<a href=(.*?)>.*?</a>',self.htmlcode)
links = []
for link in linksList:
if link.startswith('"'): link=link[1:] # 인용부호를 제거한다
if link.endswith('"'): link=link[:-1]
links.append(link)
return links
class _TestExtraction(unittest.TestCase):
def testLinksWithQuotes(self):
htmlcode = """<html><body>
Welcome to <a href="http://sebsauvage.net/">sebsauvage.net/</a><br>
How about some <a href="http://python.org">Python</a> ?</body></html>"""
le = linkextractor(htmlcode)
links = le.getLinks()
self.assertEqual(links[0], 'http://sebsauvage.net/',
'First link is %s. It should be http://sebsauvage.net/ without quotes.' % links[0])
self.assertEqual(links[1], 'http://python.org',
'Second link is %s. It should be http://python.org without quotes.' % links[1])
if __name__ == "__main__":
print "Performing self-tests..."
unittest.main()
실행하면 자가-테스트를 간단하게 할 수 있다:
Performing self-tests...
.
----------------------------------------------------------------------
Ran 1 test in 0.000s
OK
C:\>
이는 모든 프로그램/모듈/클래스/라이브러리를 자동으로 테스트하는데 (적어도 위생-점검에) 아주 유용하다.
(위의 유닛테스트는 많이 모자란다: 해야할 것이 많다. 유닛테스트에 관하여 더 배우고 싶다면, 파이썬에 뛰어들기를 읽어 보시기를 강력하게 권한다.)
두 방법 섞어 쓰는 법
자가-테스트와 명령-줄 해석을 메인에서 섞어 쓸 수도 있다:
- 명령-줄에 아무것도 주어지지 않으면 (또는 특수한
--selftest옵션에 주어지지 않으면), 자가-테스트를 수행한다. - 그렇지 않으면 사용자가 명령 줄에 요구한 것을 수행한다.
html 페이지 안의 자바스크립트를 불능화 시키는 법
웹에서 html 페이지를 잡아 오는 파이썬 프로그램이 있다면, 이 웹 페이지를 오프라인에서 열람할 때 자바스크립트가 정말 귀찮다.
다음은 모든 자바스크립트를 불능화하는 간단한 트릭이다:
짧은 버전:
개선 버전:
re_noscript = re.compile('<(/?)script',re.IGNORECASE)
html = re_noscript.sub(r'<\1noscript',html)
이렇게 하면 모든 자바스크립트가 불능이 된다 (브라우저는 그냥 <noscript> 태그를 무시한다). 원한다면 여전히 코드를 살펴볼 수 있다.
곱셈
파이썬은 곱셈을 할 수 있다. 심지어 문자열이나 터플 리스트도 곱할 수 있다.
'aaa'
>>> 3*'hello'
'hellohellohello'
>>> 3*('hello')
'hellohellohello'
>>> 3*('hello',)
('hello', 'hello', 'hello')
>>> 3*['hello']
['hello', 'hello', 'hello']
>>> 3*('hello','world')
('hello', 'world', 'hello', 'world', 'hello', 'world')
둘 사이의 차이점에 주의하자. ('hello')는 한개짜리 문자열이고 ('hello',)는 터플이다.
그 때문에 곱셈이 똑 같지 않다.
더하기도 할 수 있다:
aaabb
>>> print 3*('a',) + 2*('b',)
('a', 'a', 'a', 'b', 'b')
>>> print 3*['a'] + 2*['b']
['a', 'a', 'a', 'b', 'b']
압축파일 .tar.bz2 읽고 쓰기
tar.bz2 압축파일은 보통 .zip 또는 .tar.gz보다 작다.
파이썬은 그런 압축파일을 읽고 쓸 수 있다.
디렉토리를 .tar.bz2로 압축하기:
import bz2
archive = tarfile.open('myarchive.tar.bz2','w:bz2')
archive.debug = 1 # 압축중인 파일을 화면에 표시한다.
archive.add(r'd:\myfiles') # d:\myfiles에 압축될 파일이 들어 있다
archive.close()
.tar.bz2 압축파일 풀기:
import bz2
archive = tarfile.open('myarchive.tar.bz2','r:bz2')
archive.debug = 1 # 압축중인 파일을 화면에 표시한다.
for tarinfo in archive:
archive.extract(tarinfo, r'd:\mydirectory') # d:\mydirectory에 파일을 풀고 싶다.
archive.close()
열거하기(Enumerating)
숫자 붙여 열거하는 간단한 함수: enumerate()는 연속열에 작동한다 (문자열, 리스트...) 그리고 터플을 돌려준다 (index,item):
... print i
...
(0, 'abc')
(1, 'def')
(2, 'ghi')
(3, 'jkl')
>>>
>>> for i in enumerate('hello world'):
... print i
...
(0, 'h')
(1, 'e')
(2, 'l')
(3, 'l')
(4, 'o')
(5, ' ')
(6, 'w')
(7, 'o')
(8, 'r')
(9, 'l')
(10, 'd')
>>>
Zip that thing
zip과 map 그리고 filter는 강력한 연속열 연산자로서 어떤 경우는 지능형 리스트를 대체할 수 있다.
지능형 리스트(List comprehension)
지능형 리스트는 연속열의 원소들을 변환해 리스트를 만드는 구문이다.
예를 들어:
>>> print [value*2 for value in mylist]
[2, 6, 10, 14, 18]
다음은 거의 평범한 영어처럼 읽힌다: compute value*2 for each value in my list.
리스트를 여과하기 위해 조건을 사용할 수도 있다:
>>> print [i*2 for i in mylist if i>4]
[10, 14, 18]
리스트를 계산하고 변환하는 다른 방법도 있다: zip과 map 그리고 filter가 그것이다.
zip
zip은 터플로 구성된 리스트를 돌려준다. 각 터플에는 각 연속열(리스트, 터플 등등)의 i-번째 원소가 담긴다. 예를 들어:
[('a', 1), ('b', 2), ('c', 3)]
여러 연속열을 함께 넣을 수도 있다:
[('a', 1, 'U'), ('b', 2, 'V'), ('c', 3, 'W')]
문자열도 연속열이다. 문자열도 넣을 수 있다:
[('a', '1'), ('b', '2'), ('c', '3'), ('d', '4')]
출력 리스트는 길이가 짧은 연속열에 맞추어진다:
[(1, 'a'), (2, 'b')]
map
map은 함수를 연속열의 각 원소에 적용한 다음, 리스트를 돌려준다.
예: abs() 함수를 리스트의 각 요소에 적용해 보자:
[5, 7, 12]
이는 다음과 동등하다:
[5, 7, 12]
단 map이 더 빠르다.
독자적인 함수를 사용할 수 있다:
... return value*10+1
...
>>> print map(myfunction, [1,2,3,4] )
[11, 21, 31, 41]
>>>
여러 인자를 받는 함수를 사용할 수도 있다. 이 경우, 인자의 개수에 맞게 리스트를 제공해야 한다.
예: 두 값중 더 큰 값을 돌려주는 max() 함수를 사용한다. 연속열 2개를 제공한다.
[4, 5, 9]
이는 다음과 동등하다:
[4, 5, 9]
filter
filter는 map과 같은 일을 하는데, 단 함수에서 None을 돌려주면 (또는 None에 동등하면) 그 원소를 버리는 것이 다르다.
('동등하면'이라고 말한 까닭은 파이썬에서 0이나 빈 리스트 같은 것이 None과 동등하기 때문이다).
[-5, 7, -12]
이는 다음과 동등하다:
[-5, 7, -12]
단 filter가 더 빠르다.
그래서... map/filter인가 지능형 리스트인가?
보통 map/filter를 사용하는 것이 더 좋은데, 더 빠르기 때문이다. 그러나 언제나 빠른 것은 아니다.
다음 예제를 보자:
[0, 5, 7]
filter와 maps 그리고 lambda로 똑 같이 표현할 수 있다:
[0, 5, 7]
지능형 리스트는 읽기 쉬울 뿐만 아니라, 놀랍도록 빠르기도 하다.
언제나 코드를 윤곽잡기(profile)해서 어느 방법이 더 빠른지 살피도록 하자.
다른 연속열 연산자도 있다:
reduce
Reduce 함수는 계산 축적을 수행하는데 편리하다 (예를 들어 1+2+3+4+5 또는 1*2*3*4*5을 계산할 때).
... return a*b
...
>>> mylist = [1,2,3,4,5]
>>> print reduce(myfunction, mylist)
120
이는 다음과 동등하다:
120
사실, operator 모듈로부터 연산자를 반입할 수 있다:
>>> mylist = [1,2,3,4,5]
>>> print reduce(operator.mul, mylist)
120
>>> print reduce(operator.add, mylist)
15
(Reduce에 대한 힌트는 http://jaynes.colorado.edu/PythonIdioms.html#operator 에서 추려왔다.)
변환
리스트와 터플 그리고 사전과 문자열 사이를 변환할 수 있다. 다음은 몇가지 예이다:
>>> print list(mytuple) # 터플을 리스트로
[1, 2, 3]
>>>
>>> mylist = [1,2,3] # 리스트를 터플로
>>> print tuple(mylist)
(1, 2, 3)
>>>
>>> mylist2 = [ ('blue',5), ('red',3), ('yellow',7) ]
>>> print dict(mylist2) # 리스트를 사전으로
{'blue': 5, 'yellow': 7, 'red': 3}
>>>
>>> mystring = 'hello'
>>> print list(mystring) # 문자열을 리스트로
['h', 'e', 'l', 'l', 'o']
>>>
>>> mylist3 = ['w','or','ld']
>>> print ''.join(mylist3) # 리스트를 문자열로
world
>>>
큰 그림을 보셨다.
이는 그냥 한가지 예인데, 모두 다 연속열이기 때문이다: 예를 들어, 각 문자를 순회하기 위하여 문자열을 리스트로 변환할 필요가 없다!
>>> for character in list(mystring): # 이거 아주 나쁘다. 이렇게 하면 안된다.
... print character
...
h
e
l
l
o
>>> for character in mystring: # 그냥 이렇게 하자!
... print character
...
h
e
l
l
o
>>>
연속열 함수는 리스트는 물론이고 연속열을 요구한다는 것을 명심하자.
그리하여 다음과 같이 해도 좋다:
['H*', 'e*', 'l*', 'l*', 'o*']
또는 이렇게 해도 좋다:
w
(max() 함수도 연속열을 받는다.)
문자열은 이미 연속열이기 때문이다. 구지 문자열을 리스트로 변환할 필요가 없다.
격자를 채우는 Tkinter 위젯
tkinter 어플리케이션에서 위젯을 배치할 때, pack()이나 grid() 위치 관리자를 사용한다.Grid가 - 생각건대 - Pack보다 더 강력하고 유연한 위치 관리자이다.
(그런데, 절대로 .pack()과 .grid()를 혼용하지 말자. 안 그러면 별별 놀라운 일들을 겪을 것이다.)pack() 관리자의 (expand=1,fill=BOTH) 옵션은 창이 크기가 변할 때 위젯을 자동으로 확장시키는데 좋다. 그러나 Grid 관리자로도 똑 같이 할 수 있다.
그 방법:
grid()를 사용하면,sticky를 지정하자 (보통 'NSEW'임)- 다음
grid_columnconfigure()과grid_rowconfigure()를 사용하여 위젯을 설정하자 (보통 1).
예제: 빨간 그리고 파란 캔버스가 있는 간단한 창. 두 캔버스는 창의 모든 공간을 사용하도록 자동으로 크기가 바뀐다.
class myApplication:
def __init__(self,root):
self.root = root
self.initialisation()
def initialisation(self):
canvas1 = Tkinter.Canvas(self.root)
canvas1.config(background="red")
canvas1.grid(row=0,column=0,sticky='NSEW')
canvas2 = Tkinter.Canvas(self.root)
canvas2.config(background="blue")
canvas2.grid(row=1,column=0,sticky='NSEW')
self.root.grid_columnconfigure(0,weight=1)
self.root.grid_rowconfigure(0,weight=1)
self.root.grid_rowconfigure(1,weight=1)
def main():
root = Tkinter.Tk()
root.title('My application')
app = myApplication(root)
root.mainloop()
if __name__ == "__main__":
main()
grid_columnconfigure와 grid_rowconfigure가 있는 줄을 주석처리하면, 캔버스가 확장되지 않을 것이다.
심지어 위젯 사이에 공간을 공유하도록 공간비율(weights)을 가지고 놀 수도 있다. 예를 들어:
self.root.grid_rowconfigure(1,weight=2)
문자열 날짜를 datetime 객체로 변환하는 법
문자열 날짜(예."2006-05-18 19:35:00")를 datetime 객체로 바꾸고 싶다고 해 보자.
>>> stringDate = "2006-05-18 19:35:00"
>>> dt = datetime.datetime.fromtimestamp(time.mktime(time.strptime(stringDate,"%Y-%m-%d %H:%M:%S")))
>>> print dt
2006-05-18 19:35:00
>>> print type(dt)
<type 'datetime.datetime'>
>>>
time.strptime()는 문자열을struct_time터플로 변환한다.time.mktime()는 이 터플을 (기원 이후로 경과한 시간을 C-스타일로) 초로 변환한다.datetime.fromtimestamp()는 초를 파이썬 datetime 객체로 변환한다.
물론이다. 이는 복잡하다.
두 날짜 사이의 차를 초 단위로 계산하는 법
>>> def dateDiffInSeconds(date1, date2):
... timedelta = date2 - date1
... return timedelta.days*24*3600 + timedelta.seconds
...
>>> date1 = datetime.datetime(2006,02,17,15,30,00)
>>> date2 = datetime.datetime(2006,05,18,11,01,00)
>>> print dateDiffInSeconds(date1,date2)
7759860
>>>
관리되는 속성, 읽기-전용 속성들
가끔, 객체에서 더 섬세하게 속성에 접근하고 싶은 경우가 있다.
이렇게 하면 된다:
- 사적 속성을 하나 만든다 (
self.__x). - 이 속성에 대하여 접근 함수를 만든다 (
getx,setx,delx). property()를 만들고 접근자에 할당한다.
예제:
def __init__(self):
self.__x = None
def getx(self): return self.__x
def setx(self, value): self.__x = value
def delx(self): del self.__x
x = property(getx, setx, delx, "I'm the 'x' property.")
a = myclass()
a.x = 5 # Set
print a.x # Get
del a.x # Del
이런 식으로, getx/setx/delx 메쏘드에 접근을 제어할 수 있다.
예를 들어, 씌여지지 않도록 즉 삭제되지 않도록 특성을 보호할 수 있다:
def __init__(self):
self.__x = None
def getx(self): return self.__x
def setx(self, value): raise AttributeError,'Property x is read-only.'
def delx(self): raise AttributeError,'Property x cannot be deleted.'
x = property(getx, setx, delx, "I'm the 'x' property.")
a = myclass()
a.x = 5 # 이 줄은 실패한다
print a.x
del a.x
이 프로그램을 실행하면, 다음과 같은 결과를 얻는다:
File "example.py", line 11, in ?
a.x = 5 # This line will fail
File "example.py", line 6, in setx
def setx(self, value): raise AttributeError,'Property x is read-only.'
AttributeError: Property x is read-only.
한 달의 첫 요일 구하는 법
>>> def firstDayOfMonth(dt):
... return (dt+datetime.timedelta(days=-dt.day+1)).replace(hour=0,minute=0,second=0,microsecond=0)
...
>>> print firstDayOfMonth( datetime.datetime(2006,05,13) )
2006-05-01 00:00:00
>>>
이 함수는 datetime 객체를 입력으로 받아 (dt) 그 달의 첫 날 자정을 돌려준다 (12:00:00 AM).
6줄로 RSS 2.0 감을 가져와 해석해 읽는 법
무식하게-쉬운 버전이다.
이 프로그램은 RSS 2.0 감을 sebsauvage.net에서 얻어, 그것을 해석하여 모든 제목을 화면에 보여준다.
address = 'http://www.sebsauvage.net/rss/updates.xml'
document = xml.dom.minidom.parse(urllib.urlopen(address))
for item in document.getElementsByTagName('item'):
title = item.getElementsByTagName('title')[0].firstChild.data
print "Title:", title.encode('latin-1','replace')
BugMeNot에서 로그인 얻는 법
BugMeNot.com은 의무 등록을 요구하는 사이트에 대하여 로그인/패스워드를 제공한다.
다음은 주어진 도메인이나 URL에 대하여 로그인/패스워드를 돌려주는 간단한 함수이다.
def getLoginPassword(url):
''' BugMeNot을 사용하여 주어진 도메인에 대하여 로깅/패스워드를 돌려준다.
입력: url (string) -- 로깅을 얻을 URL 또는 도메인.
출력: 터플 (login,password)
로깅하지 못하면 (None,None) 을 돌려준다.
예제:
print getLoginPassword("http://www.nytimes.com/auth/login")
('goaway147', 'goaway')
print getLoginPassword("imdb.com")
('bobshit@mailinator.com', 'diedie')
'''
if not url.lower().startswith('http://'): url = "http://"+url
domain = urlparse.urlsplit(url)[1].split(':')[0]
address = 'http://www.bugmenot.com/view/' + domain
page = urllib.urlopen(address).read(50000)
re_loginpwd = re.compile('<th>Username.*?<td>(.+?)</td>.*?<th>Password.*?<td>(.+?)</td>',
re.IGNORECASE|re.DOTALL)
match = re_loginpwd.search(page)
if match:
return match.groups()
else:
return (None,None)
예제:
('goaway147', 'goaway')
>>> print getLoginPassword("imdb.com")
('bobshit@mailinator.com', 'diedie')
주의: BugMeNot이 가끔 에러 페이지를 보여주는 또는 로그인 할 수 없다고 알려주는 경우가 있는 것 같다. 주의하자.
사이트에 로깅해서 세션 쿠키 처리하는 법
다음은 웹 사이트에 로깅해서 세션 쿠키를 사용하여 더 요청을 하는 법을 보여주는 예이다 (imdb.com에 로그인했다).
login = 'ismellbacon123@yahoo.com'
password = 'login'
# urllib2를 위하여 쿠키 지원 활성화
cookiejar = cookielib.CookieJar()
urlOpener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookiejar))
# 로긴/패스워드를 사이트에 보내 세션 쿠키를 얻는다
values = {'login':login, 'password':password }
data = urllib.urlencode(values)
request = urllib2.Request("http://www.imdb.com/register/login", data)
url = urlOpener.open(request) # cookiejar는 자동으로 쿠키를 얻는다
page = url.read(500000)
# 쿠키 "id"가 존재하는지 점검해서 로그인 되어 있는지 확인한다.
# (이는 세션 식별자를 담고 있는 쿠키이다.)
if not 'id' in [cookie.name for cookie in cookiejar]:
raise ValueError, "Login failed with login=%s, password=%s" % (login,password)
print "We are logged in !"
# 세션 쿠키에 또다른 요청을 한다
# (urlOpener는 자동으로 cookiejar로부터 쿠키를 꺼내 사용한다 )
url = urlOpener.open('http://imdb.com/find?s=all&q=grave')
page = url.read(200000)
이 예제는 (cookielib 모듈 때문에) 파이썬 2.4 이상이 요구된다.
이제 예전 파이썬 버전에는 제-삼자 모듈로 쿠키를 지원할 수 있다 (예를 들어 ClientCookie가 있다).
로그인 폼 매개변수와 URL 그리고 세션 쿠키 이름은 웹 사이트마다 다르다. 모두 보려면 불여우(Firefox)를 사용하자:
- 폼을 보려면: Menu "Tools" > "Page info" > "Forms" tab.
- 쿠키를 보려면: Menu "Tools" > "Options" > "Privacy" tab > "Cookies" tab > "View cookies" button.
거의 대부분의 시간 동안 로그아웃할 필요가 없다.
구글 검색
다음 클래스는 구글을 검색하여 링크 리스트(URL)을 돌려준다. Google API를 사용하지 않는다.
자동으로 결과 페이지들을 열람해서, 오직 필요한 URL만 모은다.
class GoogleHarvester:
re_links = re.compile(r'<a class=l href="(.+?)"',re.IGNORECASE|re.DOTALL)
def __init__(self):
pass
def harvest(self,terms):
'''다음 조건에 대하여 구글(Google)을 검색한다. 링크만 돌려준다 (URL).
입력: 조건 (string) -- 검색할 하나 이상의 단어.
출력: url 리스트 (strings).
중복 링크는 제거되고, 링크는 정렬된다.
예제: print GoogleHarvester().harvest('monthy pythons')
'''
print "Google: Searching for '%s'" % terms
links = {}
currentPage = 0
while True:
print "Google: Querying page %d (%d links found so far)" % (currentPage/100+1, len(links))
address = "http://www.google.com/search?q=%s&num=100&hl=en&start=%d" % (urllib.quote_plus(terms),currentPage)
request = urllib2.Request(address, None, {'User-Agent':'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)'} )
urlfile = urllib2.urlopen(request)
page = urlfile.read(200000)
urlfile.close()
for url in GoogleHarvester.re_links.findall(page):
links[url] = 0
if "</div>Next</a></table></div><center>" in page: # 다음 결과 페이지에 "Next" 링크가 있는가?
currentPage += 100 # 있으면, 결과의 다음 페이지로 간다.
else:
break # 없으면, while True 회돌이를 빠져 나온다.
print "Google: Found %d links." % len(links)
return sorted(links.keys())
# 예제: "monthy pythons"를 검색한다
links = GoogleHarvester().harvest('monthy pythons')
open("links.txt","w+b").write("\n".join(links))
발견된 링크들은 links.txt 파일에 씌여진다.
주목하자. 인터넷은 언제나 진화하며, 이 프로그램을 읽을 때 쯤이면 구글이 달라질 수 있다. 그러므로 그에 맞게 이 클래스를 적응시켜야 하겠다.
Tkinter와 wxPython으로 단계별로 기본 GUI 어플리케이션을 만드는 법
다음은 GUI를 만드는 법에 관한 완전한 자습서이다. 구이를 단계별로 구축하는 법을 배워보자.
Tkinter와 wxPython을 비교한다. 각 객체와 메쏘드 매개변수를 설명한다.
http://sebsauvage.net/python/gui/
내포된 리스트와 터플을 일렬로 풀어내는 법
다음은 내포된 파일과 터플을 일렬로 풀어내는 법이다.
(이 함수는 부끄럽게도 http://www.reportlab.co.uk/cgi-bin/viewcvs.cgi/public/reportlab/trunk/reportlab/lib/utils.py에서 크게 영감을 받았다)
def flatten(L):
''' L에 내포된 리스트와 터플을 일렬로 편다(Flattens). '''
def _flatten(L,a):
for x in L:
if type(x) in (types.ListType,types.TupleType): _flatten(x,a)
else: a(x)
R = []
_flatten(L,R.append)
return R
예제:
>>> print flatten(a)
[5, 'foo', -52.5, 'bar', 'foo', 'bar', 'bar', 1, 2, 3, 4, 5, 6, 'foo', 'bar']
>>>
데이터베이스에서 거대 테이블을 효율적으로 순회하는 법
SQL 데이터베이스에서 행을 읽을 때, DB-Api에는 여러 선택이 있다:
fetchone(): 한 번에 한 행을 가져온다.fetchmany(): 한 번에 여러 행을 가져 온다.fetchall(): 한 번에 모든 행을 가져 온다.
어느 방법이 더 좋을 것 같은가?
언듯 보면, fetchall()이 좋은 생각처럼 보인다.
어디 보자: 나는 140 Mb 데이터베이스를 SQLite3 포맷으로 거대한 테이블에 가지고 있다. 한 번에 모든 행을 읽는 것이 더 빠를 것 같아 보이는가?
cur.execute('select discid,body from discussion_body;')
for row in cur.fetchall():
pass
프로그램을 실행하자 마자, 140 Mb에 이르는 메모리가 잠식된다. 헉!
왜 그러지? 왜냐하면 fetchall()은 한 번에 모든 행을 메모리에 적재하기 때문이다.
프로그램이 메모리 포식자가 되기를 원하지 않는다. 그래서 fetchall()은 별로 권장하지 않는다.
더 좋은 방법이 있다. 그래서 fetchone()으로 행단위로 읽어 보자:
cur.execute('select discid,body from discussion_body;')
for row in iter(cur.fetchone, None):
pass
fetchone()은 한 번에 한 행을 돌려주고, 더 이상 행이 없으면 None을 돌려준다: fetchone()을 for 회돌이에 사용하려면, None 값이 반환될 때까지 각 행에 대하여 fetchone()을 반복적으로 호출하는 반복자를 만들어야 한다.
잘 작동하면 메모리를 잠식하지 않는다. 그러나 최적화에는 못 미친다: 대부분의 데이터베이스는 4 Kb 데이터 패킷 정도를 사용한다. 대부분의 경우, 여러 행을 한 번에 읽는 것어 더 효율적일 것이다. 그 때문에fetchmany()를 사용한다:
cur.execute('select discid,body from discussion_body;')
for row in iter(cur.fetchmany, []):
pass
fetchmany()는 한 번에 행 리스트를 돌려준다 (변수 크기에 맞게), 그리고 더 이상 행이 없으면 빈 리스트를 돌려준다: fetchmany()를 for 회돌이에 사용하고 싶으면, 빈 리스트[]가 반환될 때까지 반복적으로fetchmany()를 호출하는 반복자를 만들어야 한다.
(한 번에 얼마나 많은 행을 가져올 지 지정하지 않았음에 주목하자: 데이터베이스 후방모듈이 알아서 최적의 임계치를 선택하도록 두는 편이 더 좋다.)fetchmany()는 행을 가져오는 최적 방식이다: fetchall()처럼 많은 메모리를 사용하지 않으며 보통fetchone()보다 더 빠르다.
예제에서 사용한 SQLite3는 네트워크-기반이 아님에 주의하자. fetchone/fetchmany 사이의 차이는 네크워크-기반의 데이터베이스(mySQL, Oracle, Microsoft SQL Server...)에서 더 크다. 왜냐하면 그런 데이터베이스들은 네트워크 패킷도 섬세하게 제어하기 때문이다.
보동소수점수의 범위
파이썬에 있는 range() 함수는 일정 범위의 정수를 생산한다.
[2, 5, 8, 11, 14]
그러나 부동소수점수는 지원하지 않는다.
다음은 부동소수점수를 지원하는 함수이다:
''' 부동소수점수의 범위를 계산한다.
입력:
start (float) : 시작 값.
end (float) : 끝 값
steps (integer): 증분 값
출력:
부동소수점수 리스트
예제:
>>> print floatrange(0.25, 1.3, 5)
[0.25, 0.51249999999999996, 0.77500000000000002, 1.0375000000000001, 1.3]
'''
return [start+float(i)*(stop-start)/(float(steps)-1) for i in range(steps)]
예제:
[0.25, 0.51249999999999996, 0.77500000000000002, 1.0375000000000001, 1.3]
RGB를 HSL로 그 반대로 변환하는 법
HSL (Hue/Saturation/Lightness)은 인간이 더 쉽게 읽을 수 있는 색상 표현이지만, 대부분의 컴퓨터는RGB 모드로 작업한다.
- Hue: 힌트 (red, blue, pink, green...)
- Saturation: 색깔이 회색으로 가는지 아니면 순수한 색상 그 자체로 가는지? (TV에서 "컬러" 설정하는 것과 비슷하다). 0=회색 1=원색.
- Lightness: 0=black, 0.5=원색, 1=white
다음은 두 컬러공간 사이를 변환하는 두 가지 함수이다. 예제는 문서화 문자열 안에 제공된다.
''' HSL 색상공간 (Hue/Saturation/Value)을 RGB 색상공간으로 변환한다.
공식은 http://www.easyrgb.com/math.php?MATH=M19#text19에서 가져옴
입력:
h (float) : Hue (0...1 까지의 범위이지만, 초과하거나 미만이어도 된다
(이는 색상환 둘레를 돌기 때문이다))
s (float) : Saturation (0...1) (0=toward grey, 1=원색)
l (float) : Lightness (0...1) (0=black 0.5=원색 1=white)
출력:
(r,g,b) (integers 0...255) : 상응하는 RGB 값
예제:
>>> print HSL_to_RGB(0.7,0.7,0.6)
(110, 82, 224)
>>> r,g,b = HSL_to_RGB(0.7,0.7,0.6)
>>> print g
82
'''
def Hue_2_RGB( v1, v2, vH ):
while vH<0.0: vH += 1.0
while vH>1.0: vH -= 1.0
if 6*vH < 1.0 : return v1 + (v2-v1)*6.0*vH
if 2*vH < 1.0 : return v2
if 3*vH < 2.0 : return v1 + (v2-v1)*((2.0/3.0)-vH)*6.0
return v1
if not (0 <= s <=1): raise ValueError,"s (saturation) parameter must be between 0 and 1."
if not (0 <= l <=1): raise ValueError,"l (lightness) parameter must be between 0 and 1."
r,b,g = (l*255,)*3
if s!=0.0:
if l<0.5 : var_2 = l * ( 1.0 + s )
else : var_2 = ( l + s ) - ( s * l )
var_1 = 2.0 * l - var_2
r = 255 * Hue_2_RGB( var_1, var_2, h + ( 1.0 / 3.0 ) )
g = 255 * Hue_2_RGB( var_1, var_2, h )
b = 255 * Hue_2_RGB( var_1, var_2, h - ( 1.0 / 3.0 ) )
return (int(round(r)),int(round(g)),int(round(b)))
def RGB_to_HSL(r,g,b):
''' RGB 색상공간을 HSL (Hue/Saturation/Value) 색상공간으로 변환한다.
공식은 http://www.easyrgb.com/math.php?MATH=M18#text18에서 가져옴
입력:
(r,g,b) (integers 0...255) : RGB values
출력:
(h,s,l) (floats 0...1): corresponding HSL values
예제:
>>> print RGB_to_HSL(110,82,224)
(0.69953051643192476, 0.69607843137254899, 0.59999999999999998)
>>> h,s,l = RGB_to_HSL(110,82,224)
>>> print s
0.696078431373
'''
if not (0 <= r <=255): raise ValueError,"r (red) parameter must be between 0 and 255."
if not (0 <= g <=255): raise ValueError,"g (green) parameter must be between 0 and 255."
if not (0 <= b <=255): raise ValueError,"b (blue) parameter must be between 0 and 255."
var_R = r/255.0
var_G = g/255.0
var_B = b/255.0
var_Min = min( var_R, var_G, var_B ) # RGB의 최소값
var_Max = max( var_R, var_G, var_B ) # RGB의 최대값
del_Max = var_Max - var_Min # RGB 증분 값
l = ( var_Max + var_Min ) / 2.0
h = 0.0
s = 0.0
if del_Max!=0.0:
if l<0.5: s = del_Max / ( var_Max + var_Min )
else: s = del_Max / ( 2.0 - var_Max - var_Min )
del_R = ( ( ( var_Max - var_R ) / 6.0 ) + ( del_Max / 2.0 ) ) / del_Max
del_G = ( ( ( var_Max - var_G ) / 6.0 ) + ( del_Max / 2.0 ) ) / del_Max
del_B = ( ( ( var_Max - var_B ) / 6.0 ) + ( del_Max / 2.0 ) ) / del_Max
if var_R == var_Max : h = del_B - del_G
elif var_G == var_Max : h = ( 1.0 / 3.0 ) + del_R - del_B
elif var_B == var_Max : h = ( 2.0 / 3.0 ) + del_G - del_R
while h < 0.0: h += 1.0
while h > 1.0: h -= 1.0
return (h,s,l)
주목하자/ h (hue)는 0...1 사이로 제한되지 않는다. 왜냐하면 색상환에서 각도이기 때문이다: 색상환을 여러 번 돌 수도 있다:-)
수정: 앗 실수 ! 물론, 파이썬에 배터리가 장착되어 있다는 사실을 까먹었다: colorsys 모듈이 이미 그런 일을 해 준다. 나를 따라해 보자: 매 뉴 얼 을 읽 자(RTFM RTFM RTFM).
무지개-빛 파스텔 칼러 팰리트 만드는 법
다음 함수는 무지개-빛 파스텔 컬러 팰리트를 생성한다.HSL_to_RGB() 함수와 floatrange() 함수를 사용함에 주목하자.
""" 서로다른 파스텔 칼러를 돌려준다.
입력:
n (integer) : 돌려줄 색상의 개수
출력:
HTML 표기법으로 된 색상 리스트 (예.['#cce0ff', '#ffcccc', '#ccffe0', '#f5ccff', '#f5ffcc'])
예제:
>>> print generatePastelColors((5)
['#cce0ff', '#f5ccff', '#ffcccc', '#f5ffcc', '#ccffe0']
"""
if n==0:
return []
# 색깔을 만들기 위하여 HSL 색상공간을 사용한다 (http://en.wikipedia.org/wiki/HSL_color_space 참조)
start_hue = 0.6 # 0=red 1/3=0.333=green 2/3=0.666=blue
saturation = 1.0
lightness = 0.9
# 색상 환 둘레의 점들을 취한다 (hue):
# (주의: n+1 컬러를 생성한 다음, 마지막 컬러는 버리는데 ([:-1]) 그 이유는 첫 컬러와 동일하기 때문이다 (hue 0 = hue 1))
return ['#%02x%02x%02x' % HSL_to_RGB(hue,saturation,lightness) for hue in floatrange(start_hue,start_hue+1,n+1)][:-1]
열을 행으로 (그 반대로) 바꾸는 법
테이블이 있다. 열을 행으로, 행을 열로 바꾸고 싶다.
간단하다:
('Zoe' , 12, 24 ),
('John' , 17, 5 ),
('Julien', 3, 11 )
]
print zip(*table)
결과는 다음과 같다:
('Disks' , 12, 17, 3 ),
('Books' , 24, 5, 11 )
]
말했다시피 쉽다:-)
파이썬에서 추상 클래스 만드는 법?
음... 파이썬은 이 "추상 클래스"라는 개념을 알지 못한다. 실제로 알 필요도 없다.
파이썬으로 "오리 형정의(duck typing)"를 사용한다: 오리처럼 꽥꽥거리면, 오리이다.
어느 추상 "duck" 클래스로부터 파생되었는지 신경쓰지 않는다. .quack() 메쏘드를 호출했을 때 꽥꽥거리기만 하면 된다..quack() 메쏘드가 있다면, 그것으로 충분하다.
어쨋거나, 추상 클래스는 계약일 뿐이다. Java나 C++ 컴파일러는 이 계약을 문법적으로 강제한다. 파이썬은 그렇지 않다. 그냥 파이썬 프로그래머가 그 계약을 존중하도록 내버려 둔다 (자, 당연히 우리가 무엇을 하는지 알아야 한다. 그렇지 않은가?).
한가지 간단한 예는 표준 에러를 파일로 방향전환하는 것이다:
class myLogger:
def __init__(self):
pass
def write(self,data):
file = open("mylog.txt","a")
file.write(data)
file.close()
sys.stderr = myLogger() # 클래스를 표준 에러에 사용한다. 콘솔 대신에 말이다.
print 5/0 # 이는 예외를 일으킨다
이는 mylog.txt 파일을 만들어 낸다. 콘솔에 에러를 표시하는 대신에 이 파일에 에러가 담긴다.
알겠는가 ?myLogger 클래스가 없어도 추상 "IOstream" 또는 "Console" 클래스로 같은 것으로부터 상속받을 수 있다: 단지.write() 메쏘드만 있으면 된다. 그것이면 된다.
그리고 작동한다!
그러나 이런 식으로 점검을 강제할 수 있다:
def __init__(self):
if self.__class__ is myAbstractClass:
raise NotImplementedError,"Class %s does not implement __init__(self)" % self.__class__
def method1(self):
raise NotImplementedError,"Class %s does not implement method1(self)" % self.__class__
파생 클래스에서 구현되지 않은 메쏘드를 호출하고 싶다면, 명시적으로 "NotImplementedError" 예외를 맞이한다.
def __init__(self):
pass
m = myClass()
m.method1()
File "myprogram.py", line 19, in <module>
m.method1()
File "myprogram.py", line 10, in method1
raise NotImplementedError,"Class %s does not implement method1(self)" % self.__class__
NotImplementedError: Class __main__.myClass does not implement method1(self)
matplotlib, PIL, 투명 PNG/GIF 그리고 ARGB와 RGBA 사이의 변환
물론이다. 조각 코드 하나에 담기에는 너무 많다. 그러나 matplotlib 또는 PIL과 작업한다면, 언젠가는 필요할 날이 있을 것이다:
- pylab을 사용하지 않고 matplotlib 그림 생성하기
- matplotlib 그림에서 투명 비트맵을 얻기
- matplotlib 그림에서 PIL 이미지 객체 얻기
- ARGB를 RGBA로 변환하기
- 투명 GIF와 PNG를 저장하기
import matplotlib, matplotlib.backends.backend_agg
import Image
# matplotlib로 그림을 만든다
figure = matplotlib.figure.Figure(frameon=False)
plot = figure.add_subplot(111)
plot.plot([1,3,2,5,6])
# 원한다면, figure.set_dpi()를 사용하여 비트맵 해상도를 바꿀 수 있다
# 또는 figure.set_size_inches()를 사용하여 크기를 바꿀 수 있다.
# 예제:
# figure.set_dpi(150)
# SciPy matplotlib 요리책도 참고하자: http://www.scipy.org/Cookbook/Matplotlib/
# 그리고 특히 다음 예제를 살펴보자:
# http://www.scipy.org/Cookbook/Matplotlib/AdjustingImageSize?action=AttachFile&do=get&target=MPL_size_test.py
# matplotlib에게 Agg 후방자원을 사용하여 그림을 비트맵을 가공하여 달라고 요청한다.
canvas = matplotlib.backends.backend_agg.FigureCanvasAgg(figure)
canvas.draw()
# 비트맵으로부터 버퍼를 얻는다
stringImage = canvas.tostring_argb()
# 버퍼를 ARGB에서 RGBA로 바꾼다:
tempBuffer = [None]*len(stringImage) # 같은 크기의 빈 배열을 stringImage로 생성한다.
tempBuffer[0::4] = stringImage[1::4]
tempBuffer[1::4] = stringImage[2::4]
tempBuffer[2::4] = stringImage[3::4]
tempBuffer[3::4] = stringImage[0::4]
stringImage = ''.join(tempBuffer)
# 변환된 RGBA 버퍼를 PIL 이미지로 바꾼다
l,b,w,h = canvas.figure.bbox.get_bounds()
im = Image.fromstring("RGBA", (int(w),int(h)), stringImage)
# 이미지를 PIL로 화면에 표시한다
im.show()
# 그것을 투명 PNG 파일로 저장한다
im.save('mychart.png')
# 투명 GIF를 원하신다면 ? 그렇게도 할 수 있다
im = im.convert('RGB').convert("P", dither=Image.NONE, palette=Image.ADAPTIVE)
# PIL ADAPTIVE 팰리트는 하얀색 (RGB=255,255,255)으로 첫 컬러 인덱스(0)를 사용하므로,
# 컬러 인덱스 0을 투명 컬러로 사용한다.
im.info["transparency"] = 0
im.save('mychart.gif',transparency=im.info["transparency"])
하얀색-아닌 배경으로 두 이미지를 모두 테스트할 수 있다:
PNG가 언제나 더 좋아 보인다. 특히 어두컴컴한 배경에서 말이다.
약점: 모든 브라우저 (IE7, Firefox, Opera, K-Meleon, Safari, Camino, Konqueror...)는 투명 PNG를 올바르게 화면가공 처리한다... 단 인터넷 익스플로러 5.5와 6을 제외하고 말이다 ! <씨익>
IE 5.5 그리고 6는 투명 PNG를 지원하지 않는다. 그래서 .GIF 포맷을 더 선호할 수도 있다. 여러분의 상황에 따라 다를 수 있다.
주의 1: ARGB에서 RGBA로의 변환에 numpy를 사용하면 더 빠를 수도 있겠지만, 연구해 보지 않았다.
주의 2: IE 5.5/6에서 투명 PNG를 지원하는 트릭이 있다. 물론 올바르게 읽으셨다. 작동할 뿐만 아니라 완벽하게 유효한 HTML 조판이다.
자동으로 이미지 다듬기
다음은 이미지 둘레의 쓸모없는 공간을 잘라 제거하는 함수이다. 특히 matplotlib에서 차트 둘레에 여분 공간을 제거하는데 편리하다.
이 함수는 투명 이미지와 불-투명 이지지를 모두 처리할 수 있다.
- 투명 이미지의 경우, 어느 정도를 다듬을지 결정하는 데 이미지 투명도가 사용된다.
- 그렇지 않으면, 이 함수는 이미지 둘레에서 가장 많이 나타나는 색상을 찾아 이 컬러를 "공백"으로 간주한다. (이 컬러를
backgroundColor매개변수로 오버라이드할 수 있다)
이 함수는 PIL 라이브러리가 필요하다.
def autoCrop(image,backgroundColor=None):
'''지능적인 자동 이미지 자르기.
이 함수는 이미지 주위에 있는 쓸모없는 "하얀색" 공간을 제거한다.
이미지에 알파 (투명) 채널이 있으면,
그것을 사용하여 무엇을 자를지 고른다.
그렇지 않으면, 이 함수는 이미지 둘레에서 가장 많은 색상을 찾으려고 시도한다.
그리고 이 색상을 "하얀공간(whitespace)"으로 간주한다.
(backgroundColor 매개변수로 이 색상을 오버라이드할 수 있다.)
입력:
image (PIL 이미지 객체): 다듬을 이미지.
backgroundColor (3개의 정수가 담긴 터플): 예 (0,0,255)
"다듬을 배경"으로 간주될 색깔.
이미지가 투명이면, 이 매개변수는 무시된다.
이미지가 투명이 아니고 이 매개변수가 주어지지 않으면,
자동으로 계산된다.
출력:
PIL 이미지 객체 : 다듬어진 이미지.
'''
def mostPopularEdgeColor(image):
''' 이미지의 둘레에서 가장 많이 나타나는 색깔이 무엇인지 계산한다.
(left,right,top,bottom)
입력:
image: PIL 이미지 객체
출력:
가장 많은 색상 (정수 터플 (R,G,B))
'''
im = image
if im.mode != 'RGB':
im = image.convert("RGB")
# 이미지의 둘레에서 픽셀을 얻는다:
width,height = im.size
left = im.crop((0,1,1,height-1))
right = im.crop((width-1,1,width,height-1))
top = im.crop((0,0,width,1))
bottom = im.crop((0,height-1,width,height))
pixels = left.tostring() + right.tostring() + top.tostring() + bottom.tostring()
# 어떤 RGB 삼중원소가 가장 많은지 계산한다
counts = {}
for i in range(0,len(pixels),3):
RGB = pixels[i]+pixels[i+1]+pixels[i+2]
if RGB in counts:
counts[RGB] += 1
else:
counts[RGB] = 1
# 가장 많은 색깔을 얻는다:
mostPopularColor = sorted([(count,rgba) for (rgba,count) in counts.items()],reverse=True)[0][1]
return ord(mostPopularColor[0]),ord(mostPopularColor[1]),ord(mostPopularColor[2])
bbox = None
# 이미지에 알파(투명) 레이어가 있으면, 그것을 사용하여 이미지를 다듬는다.
# 그렇지 않으면, 이미지 둘레에서 픽셀들을 살펴본다(위, 아래, 좌, 우)
# 그리고 가장 많이 사용된 색을 선택하여 다듬는다.
# --- 투명 이미지를 위하여 -----------------------------------------------
if 'A' in image.getbands(): # 이미지에 투명 레이어가 있으면, 그걸 사용한다.
# 이는 투명 레이어가 있는 모든 모드에 작동한다
bbox = image.split()[list(image.getbands()).index('A')].getbbox()
# --- 불-투명 이미지를 위하여 -------------------------------------------
elif image.mode=='RGB':
if not backgroundColor:
backgroundColor = mostPopularEdgeColor(image)
# 불-투명 이미지를 다듬는다.
# .getbbox()는 언제나 검정색을 다듬는다.
# 그래서 이미지에서 "배경색"을 빼줄 필요가 있다.
bg = Image.new("RGB", image.size, backgroundColor)
diff = ImageChops.difference(image, bg) # 이미지에서 배경색을 뺀다
bbox = diff.getbbox() # 이미지의 진짜 둘레를 찾는다.
else:
raise NotImplementedError, "Sorry, this function is not implemented yet for images in mode '%s'." % image.mode
if bbox:
image = image.crop(bbox)
return image
예제:
| 투명 이미지를 잘라내는 법: im = Image.open('myTransparentImage.png') cropped = autoCrop(im) cropped.show() |  |  |
| 불-투명 이미지를 잘라내는 법: im = Image.open('myImage.png') cropped = autoCrop(im) cropped.show() |  |  |
앞으로 할 것:
- 불-투명 이미지를 다른 모드로 잘라내기 (palette, black & white).
단어 세기
나타난 것들을 종류별로 세는 신속한 방법 (우리의 경우: 종류별로 사용된 단어들과 나타난 횟수):
이 같은 일은 - 예를 들어 - 크기와 이름 그리고 체크섬이 같은 파일이 얼마나 많은지 알아보는데 사용할 수 있다.
items = text.split(' ')
counters = {}
for item in items:
if item in counters:
counters[item] += 1
else:
counters[item] = 1
print "Count of different word:"
print counters
print "Most popular word:"
print sorted([(counter,word) for word,counter in counters.items()],reverse=True)[0][1]
다음과 같이 출력된다:
{'bu': 3, 'zo': 6, 'meuh': 4, 'ga': 3}
Most popular word:
zo
다음과 같이 for 회돌이를 바꾸어도 된다:
try:
counters[item] += 1
except KeyError:
counters[item] = 1
이것도 작동하지만, "if item in counters"보다 약간 더 느리다. 왜냐하면 예외 발생이라는 부담이 연루되기 때문이다 (KeyError 예외 객체를 만들어 냄).
신속한 코드 범위 검사
프로그램의 모든 부분을 검증했다고 어떻게 확신할 수 있는가? 이는 중요한 문제이다. 특히 유닛 테스트를 작성하고 있다면 말이다.
파이썬은 코드 범위 점검을 수행하는 모듈이 있다: Trace 모듈이 그것인데 문서화되어 있지 않다.
다음으로 프로그램을 실행하는 대신에:
다음과 같이 하자:
tracer = trace.Trace(ignoredirs=[sys.prefix, sys.exec_prefix],trace=0,count=1,outfile=r'./coverage_dir/counts')
tracer.run('main()')
r = tracer.results()
r.write_results(show_missing=True, coverdir=r'./coverage_dir')
이렇게 하면 coverage_dir 서브디렉토리가 생성되고 .cover 파일이 그 안에 담긴다: 이 파일들은 얼마나 많이 각 줄이 실행되었는지 알려주고, 어느 줄이 실행되지 않았는지 알려준다..cover 파일을 멋지게 HTML 페이지로 변환하려면, 다음 프로그램을 사용할 수 있다:
# -*- coding: iso-8859-1 -*-
import os,glob,cgi
def cover2html(directory=''):
''' 파이썬 Trace 모듈이 만든 .cover 파일을 .html 파일로 변환한다.
다음과 같이 cover 파일을 만들 수 있다:
import trace,sys
tracer = trace.Trace(ignoredirs=[sys.prefix, sys.exec_prefix],trace=0,count=1,outfile=r'./coverage_dir/counts')
tracer.run('main()')
r = tracer.results()
r.write_results(show_missing=True, coverdir=r'./coverage_dir')
입력:
directory (string): *.cover 파일이 있는 디렉토리.
출력:
None
html 파일은 입력 디렉토리에 씌여진다.
예제:
cover2html('coverage_dir')
'''
# 주의: 이 함수는 빠르게 & 대충 만들었다.
# CSS 파일을 쓴다:
file = open("style.css","w+")
file.write('''
body {
font-family:"Trebuchet MS",Verdana,"DejaVuSans","VeraSans",Arial,Helvetica,sans-serif;
font-size: 10pt;
background-color: white;
}
.noncovered { background-color:#ffcaca; }
.covered { }
td,th { padding-left:5px;
padding-right:5px;
border: 1px solid #ccc;
font-family:"DejaVu Sans Mono","Bitstream Vera Sans Mono",monospace;
font-size: 8pt;
}
th { font-weight:bold; background-color:#eee;}
table { border-collapse: collapse; }
''')
file.close()
indexHtml = "" # Index html table.
# .cover 파일을 html로 변환한다.
for filename in glob.glob(os.path.join(directory,'*.cover')):
print "Processing %s" % filename
filein = open(filename,'r')
htmlTable = '<table><thead><th>Run count</th><th>Line n°</th><th>Code</th></thead><tbody>'
linecounter = 0
noncoveredLineCounter = 0
for line in filein:
linecounter += 1
runcount = ''
if line[5] == ':': runcount = cgi.escape(line[:5].strip())
cssClass = 'covered'
if line.startswith('>>>>>>'):
noncoveredLineCounter += 1
cssClass="noncovered"
runcount = '►'
htmlTable += '<tr class="%s"><td align="right">%s</td><td align="right">%d</td><td nowrap>%s</td></tr>\n' % (cssClass,runcount,linecounter,cgi.escape(line[7:].rstrip()).replace(' ',' '))
filein.close()
htmlTable += '</tbody></table>'
sourceFilename = filename[:-6]+'.py'
coveragePercent = int(100*float(linecounter-noncoveredLineCounter)/float(linecounter))
html = '''<html><!-- Generated by cover2html.py - http://sebsauvage.net --><head><link rel="stylesheet" href="style.css" type="text/css"></head><body>
<b>File:</b> %s<br>
<b>Coverage:</b> %d%% ( <span class="noncovered"> ► </span> = Code not executed. )<br>
<br>
''' % (cgi.escape(sourceFilename),coveragePercent) + htmlTable + '</body></html>'
fileout = open(filename+'.html','w+')
fileout.write(html)
fileout.close()
indexHtml += '<tr><td><a href="%s">%s</a></td><td>%d%%</td></tr>\n' % (filename+'.html',cgi.escape(sourceFilename),coveragePercent)
# 다음 인덱스를 쓴다:
print "Writing index.html"
file = open('index.html','w+')
file.write('''<html><head><link rel="stylesheet" href="style.css" type="text/css"></head>
<body><table><thead><th>File</th><th>Coverage</th></thead><tbody>%s</tbody></table></body></html>''' % indexHtml)
file.close()
print "Done."
cover2html()
이 프로그램을 .cover 파일이 들어 있는 디렉토리에서 실행하고, index.html을 열어 보자.
다음은 테스트 파일과 그의 출력이다.
파이썬의 Trace 모듈은 완벽하지 않으니 주의하자: 예를 들어 실행되었음에도 불구하고 함수 정의와 기타 줄들을 그리고 반입문들을 "실행되지 않음"이라고 플래그를 붙인다.
기타 코드 범위 검사 모듈은 다음과 같다:
- Coverage: http://www.nedbatchelder.com/code/modules/coverage.html
- pyCover: http://www.geocities.com/drew_csillag/pycover.html
- FigLeaf: http://darcs.idyll.org/~t/projects/figleaf/README.html
- trace2html: http://cheeseshop.python.org/pypi/trace2html
- pycoco: http://www.livinglogic.de/Python/pycoco/index.html
wxPython에서 예외를 잡아 콘솔에 뿌리는 법
wxPython 프로그램에서 예외가 일어나면, wxPython 창에 표시된다. 가끔은, 그냥 모든 것이 콘솔(stderr)에 기록되었으면 하는 경우가 있다. 다른 파이썬 프로그램이 그러듯이 말이다. 다음은 그렇게 하는 법이다:
STDERR = sys.stderr # wxPyhon이 방향전환을 해 버리므로 stderr를 보관한다.
import wx
[...wxPython 프로그램은 여기에 둔다...]
if __name__ == "__main__":
import traceback,sys
try:
app = MyWxApplication() # 여기에서 wxPython 어플리케이션 시작.
app.MainLoop()
except:
traceback.print_exc(file=STDERR)
물론, 이 트릭을 사용하여 원한다면 모든 것들을 파일에 기록할 수 있다.
Flickr로부터 "흥미로운" 이미지들을 무작위로 얻는 법
다음은 Flickr.com에서 "흥미로운"이라는 딱지가 붙은 이미지를 무작위로 돌려주는 간단한 함수이다:
# -*- coding: iso-8859-1 -*-
import datetime,random,urllib2,re
def getInterestingFlickrImage(filename=None):
''' Flickr.com으로부터 "재미있는" 이미지를 무작위로 돌려준다.
이미지는 현재 디렉토리에 저장된다.
이미지가 유효하지 않으면 (예를 들어 사진을 얻지 못하든가 하면)
그 이미지는 저장되지 않으며 None이 반환된다.
입력:
filename (string): 선택적인 파일이름.
파일이름이 제공되지 않으면, 아무 이름이나 자동으로 공급된다.
None
출력:
(string) 파일의 이름.
이미지가 없으면 None이다.
'''
# Flickr로부터 "흥미로운" 페이지를 무작위로 얻는다:
print 'Getting a random "interesting" Flickr page...'
# flickr로부터 어제와 오늘 사이에서 무작위로 데이터를 고른다.
yesterday = datetime.datetime.now() - datetime.timedelta(days=1)
flickrStart = datetime.datetime(2004,7,1)
nbOfDays = (yesterday-flickrStart).days
randomDay = flickrStart + datetime.timedelta(days=random.randint(0,nbOfDays))
# 다음 날짜에 대하여 무작위로 페이지를 하나 얻는다.
url = 'http://flickr.com/explore/interesting/%s/page%d/' % (randomDay.strftime('%Y/%m/%d'),random.randint(1,20))
urlfile = urllib2.urlopen(url)
html = urlfile.read(500000)
urlfile.close()
# 이 페이지에서 URL들을 확보한다
re_imageurl = re.compile('src="(http://farm\d+.static.flickr.com/\d+/\d+_\w+_m.jpg)"',re.IGNORECASE|re.DOTALL)
urls = re_imageurl.findall(html)
if len(urls)==0:
raise ValueError,"Oops... could not find images URL in this page. Either Flickr has problem, or the website has changed."
urls = [url.replace('_m.jpg','_o.jpg') for url in urls]
# 무작위로 이미지를 고른다
url = random.choice(urls)
# 고른 이미지를 내려받는다:
print 'Downloading %s' % url
filein = urllib2.urlopen(url)
try:
image = filein.read(5000000)
except MemoryError: # 종종 다음 예외를 받는다. 왜인가 ?
return None
filein.close()
# 점검하자.
if len(image)==0:
return None # 가끔 flickr는 아무것도 돌려주지 않는다.
if len(image)==5000000:
return None # 너무 큰 이미지. 버린다.
if image.startswith('GIF89a'):
return None # "이 이미지는 얻을 수 없음" 이미지.
# 디스크에 저장한다.
if not filename:
filename = url[url.rindex('/')+1:]
fileout = open(filename,'w+b')
fileout.write(image)
fileout.close()
return filename
print getInterestingFlickrImage()
경고: 이 이미지들은 NSFW일 수 있다.
왜 파이썬은 초보자용 언어로 좋은가?
파이썬은 프로그래밍을 배우기에 좋은 언어이다. 왜냐하면 스크립팅 모드로 작성을 시작해서 (변수, 할당...), 새로운 개념을 배울 수 있다 (절차적 프로그래밍, 조건 분기, 회돌이, 객체 지향...).
한 가지 예를 들어보자: 간단한 프로그램으로 시작한다:
다음 입력/출력 변력과 변수를 배운다:
b = a + 2
print b
다음 절차적 프로그래밍을 배운다 (회돌이, 조건 분기...):
b = a + 2
if b > 10:
print "More than 10 !"
다음 구조적 프로그래밍을 배운다 (함수, 반환 값, 재귀...):
return value*value
print square(5)
다음 객체 지향을 배운다:
def __init__(self,value):
self.value = value
def bark(self):
print "Woof woof !"
myObject = myClass(5)
print myObject.value
myObject.bark()
등등.
이는 프로그래밍 개념을 단 번에 배우는 데 훌륭한 방법이다.
더 중요한 것은 파이썬 콘솔을 사용하여 실험하는 것이다 (파이썬은 명시적으로 컴파일을 요구하지 않기 때문이다).
파이썬이 프로그래밍 과정에 맞는지 보여주기 위하여 Slashdot 독자의 말을 인용해 보겠다:
Java:class myfirstjavaprog
{
public static void main ( String args[] )
{
System.out.println ( "Hello World!" ) ;
}
}
학생들은 이렇게 묻는다:
클래스가 뭐에요?, 우습게 보이는 괄호는 무엇인가요?, 공개가 무슨 뜻이지요?, 정적(static)이란 무엇인가요?, 무효(void)는 어디에 쓰는 건가요?, 메인(main)은 뭐지요?, 괄호는 어디에 쓰는 건가요?, 문자열이 뭐지요?, 인자는 뭐에요?, 괴상한 각괄호는 왜 있는 거에요?, 시스템이람 무엇이지요?, 점은 무슨 일을 하나요?, out이 뭐지요?, println은 무엇인가요?, 왜 인용부호가 있는 것인가요?, 쌍반점은 무엇을 하는 건가요?, 왜 저렇게 모두 들여쓰기 되어 있는 거지요?.
C:#include <stdio.h>
main()
{
printf ( "Hello, World!\n" ) ;
}
학생들은 이렇게 묻는다:
#include가 무엇인가요?, 저기에 있는 이상 이하 기호는 무엇인가요?, stdio.h가 뭔가요?, main이 뭐죠? 괄호는 어디에 쓰는 건가요?, 웃기게 생긴 괄호는 어디에 쓰는가요?, printf가 뭐지요?, 왜 hello world에 인용부호가 붙었나요?, 맨 끝에 있는 역사선-N은 무슨 일을 하는가요?, 쌍반점은 어디에 쓰는 거지요?
Python:print "Hello World"
학생들은 다음과 같이 묻습니다:
print가 뭐지요?, 왜 hello world에 인용부호가 붙었나요?
이해가 되십니까?
왜 파이썬은 초보자의 언어로 좋지 않은가.
그렇다. 몇가지 단점이 있다. 파이썬으로 시작하지 않은 사람이라면 다음 개념들을 이해하지 못할 수 있다:
- 메모리 할당 문제 (malloc/free 그리고 try/except/finally 블록). 좀 더 일반적으로 말해, 경험없는 파이썬 프로그래머라면 자원 할당 문제를 이해하지 못할 수도 있다 (파이썬 쓰레기 수집기가 대부분의 문제들을 처리해 주기 때문에 말이다 (파일 처리, 네트워크 연결, 등등.)).
- 포인터와 저-수준 연산. 파이썬은 참조와 객체만을 관리한다. 이는 더 높은-수준의 프로그래밍이다. 파이썬 프로그래머는 C나 C++의 포인터와 배열에 어려움을 겪을 수 있다. (sizeof() 좋아합니까?)
- 특정한 API. 파이썬에는 배터리가 장착되어 따라온다: 모든 플랫폼에서 API가 같다 (윈도우즈, 리눅스, 등등). 다른 언어에서는 따로 API를 가지거나 (Java), 또는 API가 플랫폼에-종속적이다(C/C++). 파이썬으로부터 온 프로그래머는 플랫폼 종속적인 특징들을 배워야 한다 (이런 특수한 것은 파이썬에서는 대부분 가려진다. 예. os.path.join())
- 정적인 유형정의. 파이썬 프로그래머는 정적으로-유형이 정의되는 언어에서 강제적인 변수와 유형 정의, 강제형변환과 결국 주형틀에 대처해야 한다 (C++, Java, C#...). 파이썬이라면 자연스럽게 할 일을 하기 위해서 말이다.
- 컴파일. 컴파일 자체는 문제가 안되지만, 부담이 되는 건 사실이다.
- 자, 파이썬을 배우고 나면 다른 언어는 고통스러울 것이다. 이 때문에 차라리 배우지 않는게 좋을 수 있다.
LDIF 파일 읽기
LDIF 파일에는 LDAP 서버에서 추출된 정보가 담긴다.
읽기 쉬워 보이지만, 독자적으로 자신만의 판독기를 만들려고 시도하지 말기를 강력 권장한다. 검증된 LDIF 클래스를 사용하는 편이 좋다.
예를 들어, http://python-ldap.sourceforge.net/에서 제공하는 LDIF 클래스를 사용할 수 있다. 이 모듈에는 경묘한 LDAP 클라이언트가 제공되지만, 단순히 LDIF 파일을 읽을 필요가 있을 뿐이라면, ldif.py파일만 취해도 된다.
다음은 사용 방법이다 (LDIF 파일에 선언된 개인의 ID와 이름 그리고 성을 화면에 표시한다.):
# -*- coding: iso-8859-1 -*-
import ldif # http://python-ldap.sourceforge.net에서 가져 온 ldif 모듈
class testParser(ldif.LDIFParser):
def __init__(self,input_file,ignored_attr_types=None,max_entries=0,process_url_schemes=None,line_sep='\n' ):
ldif.LDIFParser.__init__(self,input_file,ignored_attr_types,max_entries,process_url_schemes,line_sep)
def handle(self,dn,entry):
if 'person' in entry['objectclass']:
print "Identifier = ",entry['uid'][0]
print "FirstName = ",entry.get('givenname',[''])[0]
print "LastName = ",entry.get('sn',[''])[0]
f = open('myfile.ldif','r')
ldif_parser = testParser(f)
ldif_parser.parse()
프로그램의 출력 잡는 방법
명령-줄 프로그램의 출력을 쉽게 잡을 수 있다.
예를 들어 윈도우즈에서 워크스테이션이 송신한 바이트를 얻어보겠다. 다음 명령어로 화면에 표시된 줄에서 "Bytes received"라는 줄을 골라 보면 된다: net statistics workstation
import subprocess
myprocess = subprocess.Popen(['net','statistics','workstation'],stdout=subprocess.PIPE)
(sout,serr) = myprocess.communicate()
for line in sout.split('\n'):
if line.strip().startswith('Bytes received'):
print "This workstation received %s bytes." % line.strip().split(' ')[-1]
subprocess 모듈로도 데이터를 프로그램 입력으로 전송할 수 있음을 주목하자.
그리하여 마치 사용자가 타자한 것 같이 명령-줄 프로그램과 통신할 수 있다. (프로그램 출력을 읽었다면, 문자를 전송함으로써 응답하는 등등.)
종종, 프로그램의 반환 코드를 얻고 싶은 경우가 있다. 프로그램이 종료될 때까지 기다려야 그의 반환 값을 얻을 수 있다:
import subprocess
myprocess = subprocess.Popen(['net','statistics','workstation'],stdout=subprocess.PIPE)
(sout,serr) = myprocess.communicate()
for line in sout.split('\n'):
if line.strip().startswith('Bytes received'):
print "This workstation received %s bytes." % line.strip().split(' ')[-1]
myprocess.wait() # 프로세스가 끝나기를 기다린다
print myprocess.returncode # 다음 그의 반환코드를 얻는다.
독자적으로 웹 서버 만들기
웹서버는 상대적으로 이해하기 쉽다:
- 클라이언트(브라우저)는 웹서버에 접속해 (경로, 쿠키 등등을 포함하여) HTTP GET 또는 POST 요청을 전송한다.
- 서버는 들어온 요청(경로 (예. /some/file), 쿠키, 등등.)을 해석해 HTTP 코드로 응답한다 (404 for "not found", 200 for "ok", etc.) 그리고 웹소 자체를 전송한다 (html 페이지, 이미지...)
| 브라우저 (HTTP Client) | GET /path/hello.html HTTP/1.1 | Server (HTTP Server) |
 | ||
HTTP/1.1 200 OK
| ||
 |
자신만의 웹서버를 파이썬으로 만들고 이 과정 전체를 제어할 수 있다.
다음은 http://localhost:8088/에서 "Hello, world !"라고 응답하는 간단한 웹서버이다.
import BaseHTTPServer
class MyHandler(BaseHTTPServer.BaseHTTPRequestHandler):
def do_GET(self):
self.send_response(200)
self.send_header('Content-type','text/html')
self.end_headers()
self.wfile.write('<html><body>Hello, world !</body></html>')
return
print "Listening on port 8088..."
server = BaseHTTPServer.HTTPServer(('', 8088), MyHandler)
server.serve_forever()
- 8088 포트에 도착하는 HTTP 요청을 처리하는 클래스를 만든다 (MyHandler).
- 오직 GET 요청만 처리한다 (do_GET).
- HTTP 코드 200으로 응답한다. "만사 오케이"라는 뜻이다 (self.send_response(200)).
- 브라우저에게 HTML 데이터를 전송하겠다고 알린다 (self.send_header('Content-type','text/html')).
- 다음 HTML 자체를 전송한다 (self.wfile.write(...))
쉽다.
여기에서부터 서버를 확장하면 된다:
- 뭔가 잘못되면 특정 HTTP 에러 코드로 응답한다 (404는 "Not found", 400는 "Invalid request", 401은 "No authorized", 500은 "Internal server error", 등등)
- 요청된 경로에 따라 다르게 html을 서비스한다 (self.path).
- 파일을 디스크로부터 서비스하거나 바로바로 페이지(또는 이미지!)를 만들어서 서비스한다.
- html 데이터 (text/html), 평범한 텍스트 (text/plain), JPEG 이미지 (image/jpeg), PNG 이미지 (image/png), 등등을 전송한다.
- 쿠키를 처리한다 (self.headers에서)
- POST 요청을 처리한다 (폼이나 파일 업로드를 위한)
- 등등.
가능성은 끝이 없다.
그러나 따로 자신만의 웹서버를 작성하면 안되는 이유가 몇가지 있다:
- 손수 만든 웹서버는 한 번에 하나의 요청만 서비스할 수 있다. 전송량이 높은 웹사이트라면, 분기(fork)를 사용하거나, 쓰레드 또는 비동기 소켓을 사용해야 한다. 속도에 고도로 최적화된 웹서버가 이미 충분히 많으며 지금 작성중인 웹서버보다 훨씬 더 빠를 것이다.
- 웹서버는 환경설정 파일로 대단히 유연하다. 일일이 다 코드할 필요가 없다 (가상 경로, 가상 호스트, MIME 처리, 패스워드, 보호, 등등). 시간을 크게 절약해 준다.
- 무엇보다도 보안! 직접 만든 웹서버는 얼렁뚱땅일 가능성이 있다 (경로 해석, 등등). 보안을 특히 염두에 두고 개발된 웹서버가 많이 있다.
- 기존의 웹서버에 파이썬 코드를 병합하는 방법이 이미 많이 있다 (Apache 모듈, CGI, Fast-CGI, 등등.).
직접 웹서버를 만들어 보는 동안 재미는 있겠지만, 생산코드로 만들 생각이라면 다시 한 번 더 생각해 보자.
SOAP 클라이언트
SOAP 웹서비스를 사용해야 한다.
(물론... SOAP가 산만하다는 건 알고 있고, 손대지 않는 편이 좋다고 생각한다. 그러나 다른 방법이 없다.)
그래서, 2007년 9월 4일 현재 파이썬으로 작성된 SOAP 클라이언트의 상태를 살펴보자:
- 먼저 다음 시도: SOAPy. 헉.... 최종 갱신일이 2001년 4월 26일이라? 어쨌든 실행해 보자. 이런... 기반이
xmllib인데 이는 파이썬에서 앞으로 없어질 거라는군. 운이 없군!
다음 시도: - SOAP.py: 최종 갱신이 2005년 ? SOAPpy-0.12.0.zip를 가져와 압축을 풀고 "
python setup.py install"을 실행:SyntaxError: from __future__ imports must occur at the beginning of the file.이거 뭐야?
그런데 SOAP.py는 pyXML에 의존하고... 이는 2004년 이후로 관리가 안되고 있으며 파이썬 2.5 에서는 사용이 불가능!
이거 어떻게 해야 하나?
좋다. 다른 걸 하나 더 시도: - ZSI는 현재 관리가 되는 듯하다. 에그 파일을 내려 받아 설치...
이 시스템에는 Visual Studio 2003이 없습니다.이거 뭐야 ??!
이 파이썬 SOAP 라이브러리 하나 쓰자고 비싸고 오래된 IDE를 사서 써야 하나?
말도 안돼! - 어쩌면 4Suite가 그럴 듯해 보이는데 ?.
음... 아니다. 개발자들이 SOAP 지원을 완전히 포기한 것 같아 보인다.
그러면 이제 뭐가 남았지?
파이썬으로 작성된 SOAP 클라이언트의 상태를 보고 실망했다.
Java 그리고 .Net은 품격있는 구현이 있고, 파이썬은 없다 (적어도 윈도우즈용으로 VisualStudio를 사지 않는다면 말이다).
구글 검색을 한 후에, 훌륭한 에프보트(effbot) 페이지에서 결국 SOAP 클라이언트 구현을 찾았다:elementsoap가 바로 그것이다.
WSDL은 이재하지 못하지만, 그건 큰 문제가 아니다. 그리고 나에게는 이 정도면 충분하다.
문서는 별로 상세하지 않지만, 사용하기 아주 쉽고 잘 작동한다. 예제:
# delayed stock quote demo (www.xmethods.com)
from elementsoap.ElementSOAP import *
class QuoteService(SoapService):
url = "http://66.28.98.121:9090/soap" # 웹 서비스 URL은 여기에 둔다.
def getQuote(self, symbol):
action = "urn:xmethods-delayed-quotes#getQuote"
request = SoapRequest("{urn:xmethods-delayed-quotes}getQuote") # SOAP 요청을 만든다
SoapElement(request, "symbol", "string", symbol) # 매개변수를 추가한다
response = self.call(action, request) # 웹 서비스를 호출한다
return float(response.findtext("Result")) # 응답을 해석하여 돌려준다
q = QuoteService()
print "MSFT", q.getQuote("MSFT")
print "LNUX", q.getQuote("LNUX")
elementSoap는 좋은 로우-테크(low-tech)의 좋은 예이다: 단순한 라이브러리, 순수하게 파이썬으로 작성되었다. 오직 표준 파이썬 모듈만 사용한다 (환상적인 XML 처리 슈트에 의존하지 않는다).
요란을 떨지 않지만, 자기 일을 해 낸다.
elementSoap는 elementsoap.ElementSOAP.SoapFault 예외를 일으켜서 적절하게 SOAP 예외를 처리한다.
GMail 박스를 보관하는 법
Gmail은 깔끔하지만, 계정이 사라지면 어떻게 하는가? (그런 일이 일어나더라도... 구글은 아무 보증도 하지 않는다.)
슬픔보다는 안전이 더 낫다: 다음 코드는 전체 GMail 박스를 표준 mbox 파일에 보관한다. 그래서 쉽게 다른 이메일 클라이언트로 반입할 수 있고 저장할 수 있다.
간단하다: 실행하고, 로그인이름과 패스워드를 입력한 다음, 기다리면, yourusername.mbox 파일을 만들어 준다.
주의: 반드시 GMail 계정에서 IMAP를 활성화시켜 두어야 한다.
# -*- coding: iso-8859-1 -*-
""" GMail archiver 1.0
이 프로그램은 GMail로부터 모든 이메일을 내려받아 압축보관한다.
그냥 간단하게 로긴과 패스워드를 입력하면, 모든 이메일이
GMail로부터 다운로드되어 표준 mbox 파일에 저장된다.
여기에는 메일 받기와 전송, 보관, 어떤 것이든 적용하는대로 된다.
스팸은 내려받지 않는다.
이 mbox 파일은 나중에 아무 이메일 클라이언트로 열어 볼 수 있다 (예. Evolution).
저자:
Sébastien SAUVAGE - sebsauvage at sebsauvage dot net
Webmaster for http://sebsauvage.net/
라이센스:
이 프로그램은 OSI가-승인하는 zlib/libpng 라이센스하에 보호된다.
http://www.opensource.org/licenses/zlib-license.php
이 소프트웨어는 '있는-그대로' 제공되며, 묵시적이든 명시적이든 어떤 보증도 하지 않는다.
어떤 경우라도 이 소프트에어를 사용함으로써
야기될지 모르는 피해에 대하여 저자는 책임지지 않는다.
누구든지 상업적 어플리케이션을 포함하여 목적에 상관없이 이 소프트웨어를 사용해도 좋으며
자유롭게 변조하거나 재배포해도 된다,
다음과 같은 제한이 있다:
1. 이 소프트웨어는 출처를 꼭 밝혀야 한다;
즉 당신이 이 소프트웨어를 원래 만들었다고 주장하면 안된다. 이 소프트웨어를
상업제품에 사용한다면, 제품의 문서에 그 사실을
밝혀주면 고맙겠으나, 꼭 그럴 필요는 없다.
2. 변조된 소스는 명백하게 그 사실을 표식해야 하며
오리지날 소프트웨어라고 표현하면 안된다.
3. 이 고지는 소스 배포할 때 제거되거나 변조시키면 안 된다.
필수조건:
- IMAP이 활성화된 GMail 계정.
- Python 2.5
"""
import imaplib,getpass,os
print "GMail archiver 1.0"
user = raw_input("Enter your GMail username:")
pwd = getpass.getpass("Enter your password: ")
m = imaplib.IMAP4_SSL("imap.gmail.com")
m.login(user,pwd)
m.select("[Gmail]/All Mail")
resp, items = m.search(None, "ALL")
items = items[0].split()
print "Found %d emails." % len(items)
count = len(items)
for emailid in items:
print "Downloading email %s (%d remaining)" % (emailid,count)
resp, data = m.fetch(emailid, "(RFC822)")
email_body = data[0][1]
# 폼을 복제한다: line to the beginning of the email because mbox format requires it.
from_line = [line for line in email_body[:16384].split('\n') if line.lower().startswith('from:')][0].strip()
email_body = "From %s\n%s" % (from_line[5:].strip(),email_body)
file = open("%s.mbox"%user,"a")
file.write(email_body)
file.write("\n")
file.close()
count -= 1
print "All done."
HTTP POST 요청을 수행하는 법
urllib나 urllib2를 사용하여 HTTP 요청을 전송할 때, 기본으로 HTTP GET 요청을 전송한다. 가끔POST가 필요한 경우가 있는데, 원격 폼이 GET을 지원하지 않거나 또는 파일을 보내고 싶다거나, 요청 매개변수가 프록시 로그나 브라우저 이력에 나타내고 싶지 않기 때문이다.
다음으 그 방법이다:
import urllib,urllib2
url = 'http://www.commentcamarche.net/search/search.php3'
parameters = {'Mot' : 'Gimp'}
data = urllib.urlencode(parameters) # urllib를 사용하여 매개변수를 인코드한다
request = urllib2.Request(url, data)
response = urllib2.urlopen(request) # 다음 요청은 HTTP POST로 전송된다
page = response.read(200000)
다음은 GET 요청과 동등하다: http://www.commentcamarche.net/search/search.php3?Mot=Gimp
주목하자. 어떤 폼은 GET과 POST를 모두 받지만, 모두 그런 것은 아니다. 예를 들어, HTTP POST 요청으로는 구글을 검색할 수 없다 (구글은 요청을 거부한다).
줄 번호로 파일 읽기
파일을 읽을 때, 작업중인 줄 번호를 알고 싶은 경우가 있다. 쉽게 그렇게 할 수 있다:
for (num,value) in enumerate(file):
print "line number",num,"is:",value
file.close()
다음과 같이 출력된다:
line number 1 is: I'm a simple text file.
line number 2 is: Read me !
이는 아주 간편하다 - 예를 들어 - 파일을 반입하거나 에러가 있는 줄을 알려줄 때 말이다.
문자열에서 허용된 문자만 제외하고 모든 것을 여과하는 법
음,.. 아마도 더 좋은 방법이 있을 것이다:
>>> filtered = ''.join([c for c in mystring if c in 'abcdefghijklmnopqrstuvwxyz0123456789_-. '])
>>> print filtered
hello world. badscript
손수 웹서버 만들기 (web.py 사용)
웹서버 작성하기는 재미있을 수 있지만, 따분하다. web.py 는 멋진 최소한의 웹 작업틀로서 그 모든 일들을 단순화시켜 준다.
다음은 생각조차 필요없는 예이다:
import web
URLS = ( '/sayHelloTo/(\w+)','myfunction' )
class myfunction:
def GET(self,name):
print "Hello, %s !" % name
web.run(URLS, globals())
/sayHelloTo/(\w+)는 정규 표현식이다. 웹 서버에 도착하는 모든 URL이 이 패턴에 부합하면myfunction을 호출한다. myfunction 함수는 GET 요청을 처리하고 응답을 돌려준다.
이제 테스트해 보자: http://localhost:8080/sayHelloTo/Homer

성공이다! 단 7줄의 코드로 요청을 처리할 수 있는 페이지를 작성하였다. 멋지다.
얼마든지 원하는 만큼 URL 맵핑을 정의할 수 있다. 서버에 있는 URL을 쉽게 옮길 수도 있다. 서브 디렉토리 전체를 건드릴 필요가 없다. 여러분의 웹서버는 멋지게도 인간이-읽을 수 있는 URL을 사용한다 :-)
web.py는 html 주형틀, 데이터베이스 접근 등등을 처리하는 특징도 있다.
외부 링크
- 파이썬 관용구와 효율성: http://jaynes.colorado.edu/PythonIdioms.html
- 파이썬 속도/수행성능 팁: http://wiki.python.org/moin/PythonSpeed/PerformanceTips
- 파이썬 그리모아: http://the.taoofmac.com/static/grimoire.html
- Python Cookbook: http://aspn.activestate.com/ASPN/Python/Cookbook/
- 10 가지 파이썬 함정수: http://zephyrfalcon.org/labs/python_pitfalls.html
- 파이썬 초보자가 흔히 저지르는 실수: http://zephyrfalcon.org/labs/beginners_mistakes.html
- 파이썬 아차수: http://www.ferg.org/projects/python_gotchas.html
- Python Essays: http://www.python.org/doc/essays/
- Python FAQs: http://www.python.org/doc/faq/
- DaniWeb Python code snippets: http://www.daniweb.com/code/python.html
- "Answer My Searches" 파이썬 코드 스니핏:http://www.answermysearches.com/index.php/category/python/
- 그리고 물론 유명한 Python Eggs (링크 한 가득): http://www.python-eggs.org/

이 페이지는 http://sebsauvage.net/python/snyppets/에 있다 - 최종 갱신: 2008-05-23.
이 페이지에 있는 조각 코드는 더 쉽게 참조하기 위하여 링크되어 있다. 이 페이지를 자유롭게 링크하자.
'Development' 카테고리의 다른 글
| 파이썬 따옴표의 차이(Python "", '') (1446) | 2013.08.15 |
|---|---|
| 파이썬 개행문자 제거(Python rstrip) (1079) | 2013.08.15 |
| Python password 입력받기 (1080) | 2013.08.13 |
| Python input / raw_input 문자열 입력 (1074) | 2013.08.12 |
| Python print end=' ' parameter (2085) | 2013.08.12 |
- Total
- Today
- Yesterday
- python
- 개발
- 문제풀이
- exploit
- 프로그래밍 언어
- 파이썬
- FTZ
- www
- 티스토리
- Wargame
- CODEGATE 2014
- 프로그래밍
- 사이버테러
- 분석
- 웨일브라우저
- DoH
- CK Exploit Kit
- BOF
- 자바스크립트
- 웹
- Sublime Text 2
- network
- 스크립트
- 악성코드
- hackerschool
- DNSOverHTTPS
- CloudFlare
- TISTORY
- 해커스쿨
- writeup
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |